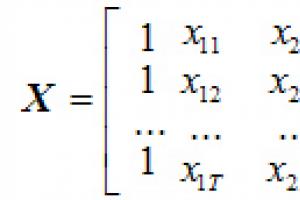Regresja liniowa. Stosując metodę najmniejszych kwadratów (LSM). Aproksymacja danych eksperymentalnych. Metoda najmniejszych kwadratów Metoda najmniejszych kwadratów w przypadku 3 zmiennych
Która znajduje najszersze zastosowanie w różnych dziedzinach nauki i praktyki. Może to być fizyka, chemia, biologia, ekonomia, socjologia, psychologia i tak dalej, i tak dalej. Zrządzeniem losu często muszę zajmować się gospodarką, dlatego dzisiaj załatwię Ci bilet do niesamowitego kraju zwanego Ekonometria=) … Jak tego nie chcesz?! Jest tam bardzo dobrze - musisz się tylko zdecydować! …Ale prawdopodobnie na pewno chcesz nauczyć się rozwiązywać problemy najmniejszych kwadratów. A szczególnie pilni czytelnicy nauczą się je rozwiązywać nie tylko dokładnie, ale i BARDZO SZYBKO ;-) Ale najpierw ogólne przedstawienie problemu+ powiązany przykład:
Niech badane będą wskaźniki w jakimś obszarze tematycznym, które mają wyraz ilościowy. Jednocześnie istnieją podstawy, aby sądzić, że wskaźnik zależy od wskaźnika. Założenie to może mieć charakter zarówno hipotezy naukowej, jak i opierać się na elementarnym zdrowym rozsądku. Zostawmy jednak naukę na boku i zajmijmy się bardziej apetycznymi rejonami – czyli sklepami spożywczymi. Oznacz przez:
– powierzchnia handlowa sklepu spożywczego, mkw.,
- roczny obrót sklepu spożywczego, miliony rubli.
Dość oczywiste jest, że im większa powierzchnia sklepu, tym w większości przypadków większe są jego obroty.
Załóżmy, że po przeprowadzeniu obserwacji/eksperymentów/obliczeń/tańczenia z tamburynem dysponujemy danymi liczbowymi: 
W przypadku sklepów spożywczych myślę, że wszystko jest jasne: - jest to powierzchnia pierwszego sklepu, - jego roczny obrót, - powierzchnia drugiego sklepu, - jego roczny obrót itp. Notabene posiadanie dostępu do materiałów niejawnych wcale nie jest konieczne – dość dokładną ocenę obrotów można uzyskać korzystając statystyka matematyczna. Jednak nie rozpraszaj się, przebieg szpiegostwa komercyjnego jest już opłacony =)
Dane tabelaryczne można również zapisać w postaci punktów i przedstawić w zwykły dla nas sposób. Układ kartezjański .
Odpowiedzmy sobie na ważne pytanie: ile punktów potrzeba do badania jakościowego?
Im większy tym lepszy. Minimalny dopuszczalny set to 5-6 punktów. Ponadto przy małej ilości danych nie należy uwzględniać w próbie wyników „nieprawidłowych”. Na przykład mały elitarny sklep może pomóc o rząd wielkości bardziej niż „jego koledzy”, zniekształcając w ten sposób ogólny wzorzec, który należy znaleźć!
Jeśli jest to całkiem proste, musimy wybrać funkcję, harmonogram który przechodzi jak najbliżej punktów ![]() . Taka funkcja nazywa się przybliżanie
(przybliżenie - przybliżenie) Lub funkcja teoretyczna
. Ogólnie rzecz biorąc, tutaj od razu pojawia się oczywisty „pretendent” - wielomian wysokiego stopnia, którego wykres przechodzi przez WSZYSTKIE punkty. Ale ta opcja jest skomplikowana i często po prostu niepoprawna. (ponieważ wykres będzie się cały czas „nawijał” i słabo odzwierciedlał główny trend).
. Taka funkcja nazywa się przybliżanie
(przybliżenie - przybliżenie) Lub funkcja teoretyczna
. Ogólnie rzecz biorąc, tutaj od razu pojawia się oczywisty „pretendent” - wielomian wysokiego stopnia, którego wykres przechodzi przez WSZYSTKIE punkty. Ale ta opcja jest skomplikowana i często po prostu niepoprawna. (ponieważ wykres będzie się cały czas „nawijał” i słabo odzwierciedlał główny trend).
Zatem pożądana funkcja musi być wystarczająco prosta i jednocześnie odpowiednio odzwierciedlać zależność. Jak można się domyślić, jedna z metod znajdowania takich funkcji nazywa się najmniejszych kwadratów. Najpierw przeanalizujmy jego istotę w sposób ogólny. Niech jakaś funkcja przybliży dane eksperymentalne: 
Jak ocenić dokładność tego przybliżenia? Obliczmy także różnice (odchylenia) pomiędzy wartościami doświadczalnymi i funkcjonalnymi (studiujemy rysunek). Pierwszą myślą, która przychodzi na myśl, jest oszacowanie, jak duża jest to suma, problem jednak polega na tym, że różnice mogą być ujemne. (Na przykład, ![]() )
a odchylenia powstałe w wyniku takiego sumowania będą się wzajemnie znosić. Dlatego też jako oszacowanie dokładności przybliżenia sugeruje się przyjęcie sumy moduły odchylenia:
)
a odchylenia powstałe w wyniku takiego sumowania będą się wzajemnie znosić. Dlatego też jako oszacowanie dokładności przybliżenia sugeruje się przyjęcie sumy moduły odchylenia:
![]() lub w formie złożonej: (nagle, kto nie wie: jest ikoną sumy i jest zmienną pomocniczą-„licznikiem”, która przyjmuje wartości od 1 do ).
lub w formie złożonej: (nagle, kto nie wie: jest ikoną sumy i jest zmienną pomocniczą-„licznikiem”, która przyjmuje wartości od 1 do ).
Aproksymując punkty eksperymentalne różnymi funkcjami, otrzymamy różne wartości , a oczywiste jest, że tam, gdzie ta suma jest mniejsza, funkcja ta jest dokładniejsza.
Taka metoda istnieje i nazywa się metoda najmniejszego modułu. Jednak w praktyce stało się to znacznie bardziej powszechne. metoda najmniejszych kwadratów, w którym możliwe wartości ujemne są eliminowane nie przez moduł, ale przez podniesienie odchyleń do kwadratu:
![]() , po czym dąży się do wyboru takiej funkcji, która będzie sumą kwadratów odchyleń
, po czym dąży się do wyboru takiej funkcji, która będzie sumą kwadratów odchyleń ![]() był tak mały, jak to tylko możliwe. Właściwie stąd nazwa metody.
był tak mały, jak to tylko możliwe. Właściwie stąd nazwa metody.
A teraz wracamy do innego ważnego punktu: jak wspomniano powyżej, wybrana funkcja powinna być dość prosta - ale takich funkcji jest również wiele: liniowy , hiperboliczny, wykładniczy, logarytmiczny, kwadratowy itp. I oczywiście tutaj chciałbym od razu „zmniejszyć pole działania”. Jaką klasę funkcji wybrać do badań? Prymitywna, ale skuteczna technika:
- Najłatwiejszy sposób na rysowanie punktów ![]() na rysunku i przeanalizuj ich położenie. Jeśli mają tendencję do ustawiania się w linii prostej, powinieneś poszukać równanie linii prostej
na rysunku i przeanalizuj ich położenie. Jeśli mają tendencję do ustawiania się w linii prostej, powinieneś poszukać równanie linii prostej ![]() z optymalnymi wartościami i . Innymi słowy zadanie polega na znalezieniu TAKICH współczynników - aby suma kwadratów odchyleń była jak najmniejsza.
z optymalnymi wartościami i . Innymi słowy zadanie polega na znalezieniu TAKICH współczynników - aby suma kwadratów odchyleń była jak najmniejsza.
Jeśli punkty znajdują się np. wzdłuż hiperbola, to jasne jest, że funkcja liniowa daje słabe przybliżenie. W tym przypadku szukamy najbardziej „korzystnych” współczynników dla równania hiperboli ![]() - te, które dają minimalną sumę kwadratów
- te, które dają minimalną sumę kwadratów  .
.
Teraz zauważ, że w obu przypadkach mówimy funkcje dwóch zmiennych, którego argumentami są przeszukane opcje zależności:
Zasadniczo musimy rozwiązać standardowy problem - znaleźć minimum funkcji dwóch zmiennych.
Przypomnijmy nasz przykład: załóżmy, że punkty „sklepowe” zwykle leżą w linii prostej i istnieją podstawy, by sądzić, że zależność liniowa obrotów z obszaru handlowego. Znajdźmy TAKIE współczynniki „a” i „be”, aby uzyskać sumę kwadratów odchyleń ![]() był najmniejszy. Wszystko jak zwykle – najpierw pochodne cząstkowe pierwszego rzędu. Według reguła liniowości możesz rozróżnić bezpośrednio pod ikoną sumy:
był najmniejszy. Wszystko jak zwykle – najpierw pochodne cząstkowe pierwszego rzędu. Według reguła liniowości możesz rozróżnić bezpośrednio pod ikoną sumy: 
Jeśli chcesz wykorzystać te informacje w eseju lub pracy semestralnej, będę bardzo wdzięczny za link w wykazie źródeł, tak szczegółowych obliczeń nie znajdziesz nigdzie: 
Stwórzmy standardowy system: 
Każde równanie redukujemy o „dwa” i dodatkowo „rozbijamy” sumy: 
Notatka
: niezależnie przeanalizuj, dlaczego „a” i „być” można usunąć z ikony sumy. Nawiasem mówiąc, formalnie można to zrobić za pomocą sumy![]()
Przepiszmy system w formie „stosowanej”: 
po czym zaczyna się rysować algorytm rozwiązania naszego problemu:
Czy znamy współrzędne punktów? Wiemy. Sumy ![]() możemy znaleźć? Łatwo. Komponujemy najprościej układ dwóch równań liniowych z dwiema niewiadomymi(„a” i „beh”). Rozwiązujemy układ np. Metoda Cramera, co daje punkt stacjonarny . Kontrola warunek wystarczający na ekstremum, możemy sprawdzić, że w tym momencie funkcja
możemy znaleźć? Łatwo. Komponujemy najprościej układ dwóch równań liniowych z dwiema niewiadomymi(„a” i „beh”). Rozwiązujemy układ np. Metoda Cramera, co daje punkt stacjonarny . Kontrola warunek wystarczający na ekstremum, możemy sprawdzić, że w tym momencie funkcja ![]() dociera dokładnie minimum. Weryfikacja wiąże się z dodatkowymi obliczeniami, dlatego pozostawimy ją w tle. (w razie potrzeby można obejrzeć brakującą klatkę). Wyciągamy ostateczny wniosek:
dociera dokładnie minimum. Weryfikacja wiąże się z dodatkowymi obliczeniami, dlatego pozostawimy ją w tle. (w razie potrzeby można obejrzeć brakującą klatkę). Wyciągamy ostateczny wniosek:
Funkcjonować ![]() Najlepszym sposobem (przynajmniej w porównaniu z jakąkolwiek inną funkcją liniową) przybliża punkty doświadczalne
Najlepszym sposobem (przynajmniej w porównaniu z jakąkolwiek inną funkcją liniową) przybliża punkty doświadczalne ![]() . Z grubsza rzecz biorąc, jego wykres przebiega jak najbliżej tych punktów. W tradycji ekonometria wynikowa funkcja aproksymująca jest również nazywana sparowane równanie regresji liniowej
.
. Z grubsza rzecz biorąc, jego wykres przebiega jak najbliżej tych punktów. W tradycji ekonometria wynikowa funkcja aproksymująca jest również nazywana sparowane równanie regresji liniowej
.
Rozważany problem ma duże znaczenie praktyczne. W sytuacji z naszego przykładu równanie ![]() pozwala przewidzieć, jaki rodzaj obrotów („yig”) będzie w sklepie z taką czy inną wartością powierzchni sprzedaży (takie czy inne znaczenie „x”). Tak, wynikowa prognoza będzie tylko prognozą, ale w wielu przypadkach okaże się dość dokładna.
pozwala przewidzieć, jaki rodzaj obrotów („yig”) będzie w sklepie z taką czy inną wartością powierzchni sprzedaży (takie czy inne znaczenie „x”). Tak, wynikowa prognoza będzie tylko prognozą, ale w wielu przypadkach okaże się dość dokładna.
Przeanalizuję tylko jeden problem z liczbami „prawdziwymi”, ponieważ nie ma w nim żadnych trudności - wszystkie obliczenia są na poziomie programu szkolnego w klasach 7-8. W 95 procentach przypadków zostaniesz poproszony o znalezienie tylko funkcji liniowej, ale na samym końcu artykułu pokażę, że znalezienie równań optymalnej hiperboli, wykładnika i niektórych innych funkcji nie jest już trudniejsze.
Tak naprawdę pozostaje rozdać obiecane gadżety - abyś nauczył się rozwiązywać takie przykłady nie tylko dokładnie, ale i szybko. Dokładnie badamy standard:
Zadanie
W wyniku badania zależności pomiędzy dwoma wskaźnikami otrzymano następujące pary liczb: 
Korzystając z metody najmniejszych kwadratów, znajdź funkcję liniową, która najlepiej przybliża funkcję empiryczną (doświadczony) dane. Wykonaj rysunek, na którym w prostokątnym układzie współrzędnych kartezjańskich narysuj punkty doświadczalne i wykres funkcji aproksymującej ![]() . Znajdź sumę kwadratów odchyleń między wartościami empirycznymi i teoretycznymi. Dowiedz się, czy funkcja jest lepsza (wg metody najmniejszych kwadratów) przybliżone punkty doświadczalne.
. Znajdź sumę kwadratów odchyleń między wartościami empirycznymi i teoretycznymi. Dowiedz się, czy funkcja jest lepsza (wg metody najmniejszych kwadratów) przybliżone punkty doświadczalne.
Zauważ, że wartości „x” są wartościami naturalnymi i ma to charakterystyczne znaczenie znaczące, o czym opowiem nieco później; ale oczywiście mogą być ułamkowe. Ponadto, w zależności od treści konkretnego zadania, zarówno wartości „X”, jak i „G” mogą być całkowicie lub częściowo ujemne. Cóż, dostaliśmy zadanie „bez twarzy” i zaczynamy je rozwiązanie:
Znajdujemy współczynniki funkcji optymalnej jako rozwiązanie układu: 
Dla bardziej zwięzłego zapisu zmienną „licznik” można pominąć, ponieważ jest już jasne, że sumowanie odbywa się od 1 do .
Wygodniej jest obliczyć wymagane kwoty w formie tabelarycznej: 
Obliczenia można przeprowadzić na mikrokalkulatorze, ale znacznie lepiej jest korzystać z Excela - zarówno szybciej, jak i bez błędów; obejrzyj krótki film:
W ten sposób otrzymujemy, co następuje system:![]()
Tutaj możesz pomnożyć drugie równanie przez 3 i odejmij drugie od pierwszego równania wyraz po wyrazie. Ale to szczęście - w praktyce systemy często nie są obdarowane, a w takich przypadkach oszczędza Metoda Cramera:
, więc system ma unikalne rozwiązanie.

Zróbmy kontrolę. Rozumiem, że nie chcę, ale po co pomijać błędy tam, gdzie absolutnie nie można ich przeoczyć? Podstaw znalezione rozwiązanie po lewej stronie każdego równania układu:
Otrzymuje się właściwe części odpowiednich równań, co oznacza, że układ został rozwiązany poprawnie.
Zatem pożądana funkcja aproksymująca: – od wszystkie funkcje liniowe dane eksperymentalne są przez nią najlepiej przybliżone.
w odróżnieniu prosty
zależności obrotów sklepu od jego powierzchni, znaleziona zależność wynosi odwracać
(zasada „im więcej – tym mniej”), a fakt ten jest natychmiast ujawniany przez negatyw współczynnik kątowy. Funkcjonować ![]() informuje nas, że wraz ze wzrostem pewnego wskaźnika o 1 jednostkę wartość wskaźnika zależnego maleje przeciętny o 0,65 jednostki. Jak mówią, im wyższa cena gryki, tym mniej się sprzedaje.
informuje nas, że wraz ze wzrostem pewnego wskaźnika o 1 jednostkę wartość wskaźnika zależnego maleje przeciętny o 0,65 jednostki. Jak mówią, im wyższa cena gryki, tym mniej się sprzedaje.
Aby wykreślić funkcję aproksymującą, znajdujemy dwie jej wartości:
i wykonaj rysunek: 
Zbudowana linia nazywa się linia trendu
(mianowicie liniowa linia trendu, tj. w ogólnym przypadku trend niekoniecznie jest linią prostą). Każdemu znane jest wyrażenie „być w trendzie” i myślę, że to określenie nie wymaga dodatkowego komentarza.
Oblicz sumę kwadratów odchyleń ![]() pomiędzy wartościami empirycznymi i teoretycznymi. Geometrycznie jest to suma kwadratów długości odcinków „karmazynowych”. (z których dwa są tak małe, że nawet ich nie widać).
pomiędzy wartościami empirycznymi i teoretycznymi. Geometrycznie jest to suma kwadratów długości odcinków „karmazynowych”. (z których dwa są tak małe, że nawet ich nie widać).
Podsumujmy obliczenia w tabeli: 
Można je ponownie wykonać ręcznie, na wszelki wypadek podam przykład dla punktu 1: ![]()
ale o wiele bardziej wydajne jest wykonanie już znanego sposobu:
Powtórzmy: jakie jest znaczenie wyniku? Z wszystkie funkcje liniowe funkcjonować ![]() wykładnik jest najmniejszy, to znaczy jest najlepszym przybliżeniem w swojej rodzinie. I tutaj, nawiasem mówiąc, ostatnie pytanie problemu nie jest przypadkowe: co by było, gdyby proponowana funkcja wykładnicza
wykładnik jest najmniejszy, to znaczy jest najlepszym przybliżeniem w swojej rodzinie. I tutaj, nawiasem mówiąc, ostatnie pytanie problemu nie jest przypadkowe: co by było, gdyby proponowana funkcja wykładnicza ![]() czy lepiej będzie przybliżyć punkty doświadczalne?
czy lepiej będzie przybliżyć punkty doświadczalne?
Znajdźmy odpowiednią sumę kwadratów odchyleń - dla ich rozróżnienia oznaczę je literą „epsilon”. Technika jest dokładnie taka sama: 
I znowu dla każdego obliczenia pożaru dla 1. punktu: 
W Excelu używamy funkcji standardowej DO POTĘGI (Składnię można znaleźć w Pomocy programu Excel).
Wniosek: , więc funkcja wykładnicza przybliża punkty eksperymentalne gorzej niż linia prosta ![]() .
.
Ale należy tutaj zauważyć, że „gorsze” jest nie znaczy jeszcze, co jest nie tak. Teraz zbudowałem wykres tej funkcji wykładniczej - i ona również przechodzi blisko punktów ![]() - do tego stopnia, że bez badań analitycznych trudno stwierdzić, która funkcja jest dokładniejsza.
- do tego stopnia, że bez badań analitycznych trudno stwierdzić, która funkcja jest dokładniejsza.
To kończy rozwiązanie i wracam do pytania o naturalne wartości argumentu. W różnych badaniach, z reguły ekonomicznych lub socjologicznych, miesiące, lata lub inne równe przedziały czasowe są numerowane naturalnym „X”. Rozważmy na przykład taki problem.
Przykład.
Dane eksperymentalne dotyczące wartości zmiennych X I Na podano w tabeli.
W wyniku ich wyrównania powstaje funkcja ![]()
Za pomocą metoda najmniejszych kwadratów, aproksymuj te dane za pomocą zależności liniowej y=topór+b(znajdź parametry A I B). Dowiedz się, która z dwóch linii lepiej (w sensie metody najmniejszych kwadratów) wyrównuje dane eksperymentalne. Narysuj coś.
Istota metody najmniejszych kwadratów (LSM).
Problem polega na znalezieniu współczynników zależności liniowej dla których spełnia się funkcja dwóch zmiennych A I B
![]() przyjmuje najmniejszą wartość. To znaczy, biorąc pod uwagę dane A I B suma kwadratów odchyleń danych eksperymentalnych od znalezionej prostej będzie najmniejsza. Na tym polega cały sens metody najmniejszych kwadratów.
przyjmuje najmniejszą wartość. To znaczy, biorąc pod uwagę dane A I B suma kwadratów odchyleń danych eksperymentalnych od znalezionej prostej będzie najmniejsza. Na tym polega cały sens metody najmniejszych kwadratów.
Zatem rozwiązanie przykładu sprowadza się do znalezienia ekstremum funkcji dwóch zmiennych.
Wyprowadzenie wzorów na znalezienie współczynników.
Układ dwóch równań z dwiema niewiadomymi jest kompilowany i rozwiązywany. Znajdowanie pochodnych cząstkowych funkcji ![]() przez zmienne A I B, przyrównujemy te pochodne do zera.
przez zmienne A I B, przyrównujemy te pochodne do zera. 
Powstały układ równań rozwiązujemy dowolną metodą (np metoda substytucyjna Lub Metoda Cramera) i otrzymać wzory na znalezienie współczynników metodą najmniejszych kwadratów (LSM). 
Z danymi A I B funkcjonować ![]() przyjmuje najmniejszą wartość. Podano dowód tego faktu pod tekstem na końcu strony.
przyjmuje najmniejszą wartość. Podano dowód tego faktu pod tekstem na końcu strony.
To cała metoda najmniejszych kwadratów. Wzór na znalezienie parametru A zawiera sumy ,, i parametr N- ilość danych eksperymentalnych. Wartości tych sum zaleca się obliczać osobno. Współczynnik B znalezione po obliczeniach A.
Czas przypomnieć sobie oryginalny przykład.
Rozwiązanie.
W naszym przykładzie n=5. Wypełniamy tabelę dla wygody obliczenia kwot zawartych we wzorach wymaganych współczynników. 
Wartości w czwartym wierszu tabeli uzyskuje się poprzez pomnożenie wartości drugiego wiersza przez wartości trzeciego wiersza dla każdej liczby I.
Wartości w piątym wierszu tabeli uzyskuje się przez podniesienie do kwadratu wartości z drugiego wiersza dla każdej liczby I.
Wartości ostatniej kolumny tabeli są sumami wartości w wierszach.
Do znalezienia współczynników używamy wzorów metody najmniejszych kwadratów A I B. Podstawiamy w nich odpowiednie wartości z ostatniej kolumny tabeli: 
Stąd, y=0,165x+2,184 jest pożądaną przybliżoną linią prostą.
Pozostaje dowiedzieć się, która z linii y=0,165x+2,184 Lub ![]() lepiej przybliża dane oryginalne, czyli dokonuje oszacowania metodą najmniejszych kwadratów.
lepiej przybliża dane oryginalne, czyli dokonuje oszacowania metodą najmniejszych kwadratów.
Oszacowanie błędu metody najmniejszych kwadratów.
Aby to zrobić, musisz obliczyć sumę kwadratów odchyleń oryginalnych danych od tych linii ![]() I
I ![]() , mniejsza wartość odpowiada linii, która lepiej przybliża oryginalne dane metodą najmniejszych kwadratów.
, mniejsza wartość odpowiada linii, która lepiej przybliża oryginalne dane metodą najmniejszych kwadratów. 
Od , następnie linia y=0,165x+2,184 lepiej przybliża oryginalne dane.
Graficzna ilustracja metody najmniejszych kwadratów (LSM).
Na wykresach wszystko wygląda świetnie. Czerwona linia to znaleziona linia y=0,165x+2,184, niebieska linia to ![]() , różowe kropki to oryginalne dane.
, różowe kropki to oryginalne dane.

W praktyce przy modelowaniu różnych procesów - w szczególności ekonomicznych, fizycznych, technicznych, społecznych - powszechnie stosuje się tę lub inną metodę obliczania przybliżonych wartości funkcji na podstawie ich znanych wartości w niektórych stałych punktach.
Często pojawiają się problemy aproksymacji funkcji tego rodzaju:
przy konstruowaniu przybliżonych wzorów do obliczania wartości wielkości charakterystycznych badanego procesu na podstawie danych tabelarycznych uzyskanych w wyniku eksperymentu;
w całkowaniu numerycznym, różniczkowaniu, rozwiązywaniu równań różniczkowych itp.;
jeśli konieczne jest obliczenie wartości funkcji w punktach pośrednich rozpatrywanego przedziału;
przy określaniu wartości wielkości charakterystycznych procesu poza rozpatrywanym przedziałem, w szczególności podczas prognozowania.
Jeżeli w celu zamodelowania pewnego procesu określonego w tabeli zostanie skonstruowana funkcja, która w przybliżeniu opisuje ten proces metodą najmniejszych kwadratów, będzie to nazywać się funkcją aproksymującą (regresją), a samo zadanie konstruowania funkcji aproksymujących będzie być problemem przybliżenia.
W artykule omówiono możliwości pakietu MS Excel do rozwiązywania takich problemów, ponadto podano metody i techniki konstruowania (tworzenia) regresji dla danych tabelarycznych (co jest podstawą analizy regresji).
Istnieją dwie możliwości tworzenia regresji w programie Excel.
Dodanie wybranych regresji (linii trendu) do wykresu zbudowanego na podstawie tabeli danych dla badanej charakterystyki procesu (dostępne tylko w przypadku zbudowania wykresu);
Wykorzystanie wbudowanych funkcji statystycznych arkusza Excel, które umożliwiają uzyskanie regresji (linii trendu) bezpośrednio z tabeli danych źródłowych.
Dodawanie linii trendu do wykresu
W przypadku tabeli danych opisujących określony proces i przedstawionych w postaci diagramu Excel posiada skuteczne narzędzie do analizy regresji, które pozwala:
zbuduj w oparciu o metodę najmniejszych kwadratów i dodaj do diagramu pięć rodzajów regresji, które modelują badany proces z różnym stopniem dokładności;
dodać do diagramu równanie skonstruowanej regresji;
określić stopień zgodności wybranej regresji z danymi wyświetlanymi na wykresie.
Na podstawie danych wykresu Excel umożliwia uzyskanie liniowych, wielomianowych, logarytmicznych, wykładniczych, wykładniczych typów regresji, które są określone równaniem:
y = y(x)
gdzie x jest zmienną niezależną, która często przyjmuje wartości ciągu liczb naturalnych (1; 2; 3; ...) i daje na przykład odliczenie czasu badanego procesu (charakterystyka) .
1 . Regresja liniowa jest dobra w modelowaniu cech, które rosną lub maleją ze stałą szybkością. Jest to najprostszy model badanego procesu. Jest on zbudowany według równania:
y=mx+b
gdzie m jest tangensem nachylenia regresji liniowej do osi x; b - współrzędna punktu przecięcia regresji liniowej z osią y.
2 . Wielomianowa linia trendu jest przydatna do opisywania cech, które mają kilka różnych ekstremów (wzloty i upadki). O wyborze stopnia wielomianu decyduje liczba ekstremów badanej cechy. Zatem wielomian drugiego stopnia może dobrze opisać proces, który ma tylko jedno maksimum lub minimum; wielomian trzeciego stopnia - nie więcej niż dwa ekstrema; wielomian czwartego stopnia - nie więcej niż trzy ekstrema itp.
W tym przypadku linia trendu budowana jest zgodnie z równaniem:
y = c0 + c1x + c2x2 + c3x3 + c4x4 + c5x5 + c6x6
gdzie współczynniki c0, c1, c2,... c6 są stałymi, których wartości wyznaczane są w trakcie budowy.
3 . Logarytmiczna linia trendu jest z powodzeniem stosowana w modelowaniu charakterystyk, których wartości początkowo zmieniają się szybko, a następnie stopniowo stabilizują.
y = do ln(x) + b
4 . Linia trendu mocy daje dobre wyniki, jeśli wartości badanej zależności charakteryzują się stałą zmianą tempa wzrostu. Przykładem takiej zależności może być wykres ruchu samochodu z jednostajnym przyspieszeniem. Jeśli w danych znajdują się wartości zerowe lub ujemne, nie można użyć linii trendu mocy.
Jest on zbudowany zgodnie z równaniem:
y = cxb
gdzie współczynniki b, c są stałymi.
5 . Jeśli tempo zmian danych stale rośnie, należy zastosować wykładniczą linię trendu. W przypadku danych zawierających wartości zerowe lub ujemne tego rodzaju przybliżenie również nie ma zastosowania.
Jest on zbudowany zgodnie z równaniem:
y=cebx
gdzie współczynniki b, c są stałymi.
Wybierając linię trendu, Excel automatycznie oblicza wartość R2, która charakteryzuje dokładność aproksymacji: im wartość R2 jest bliższa jedności, tym bardziej wiarygodnie linia trendu przybliża badany proces. W razie potrzeby wartość R2 można zawsze wyświetlić na wykresie.
Określone według wzoru:

Aby dodać linię trendu do serii danych:
aktywuj wykres zbudowany na podstawie serii danych, czyli kliknij w obszarze wykresu. W menu głównym pojawi się pozycja Wykres;
po kliknięciu tej pozycji na ekranie pojawi się menu, w którym należy wybrać polecenie Dodaj linię trendu.
Te same działania można łatwo wdrożyć, jeśli najedziesz kursorem na wykres odpowiadający jednej z serii danych i klikniesz prawym przyciskiem myszy; w wyświetlonym menu kontekstowym wybierz polecenie Dodaj linię trendu. Na ekranie pojawi się okno dialogowe Trendline z otwartą zakładką Type (rys. 1).

Następnie potrzebujesz:
Na karcie Typ wybierz wymagany typ linii trendu (domyślnie wybrana jest opcja Liniowa). W przypadku typu Wielomian w polu Stopień określ stopień wybranego wielomianu.
1 . Pole Zbudowane na serii zawiera listę wszystkich serii danych na danym wykresie. Aby dodać linię trendu do określonej serii danych, wybierz jej nazwę w polu Zbudowana na serii.

W razie potrzeby wchodząc w zakładkę Parametry (rys. 2) można ustawić następujące parametry linii trendu:
zmienić nazwę linii trendu w polu Nazwa krzywej aproksymowanej (wygładzonej).
w polu Prognoza ustaw liczbę okresów (do przodu lub do tyłu) prognozy;
wyświetlić równanie linii trendu w obszarze wykresu, dla którego należy zaznaczyć checkbox pokaż równanie na wykresie;
wyświetlić w obszarze wykresu wartość wiarygodności aproksymacji R2, dla której należy zaznaczyć checkbox, umieścić na wykresie wartość wiarygodności aproksymacji (R^2);
ustawić punkt przecięcia linii trendu z osią Y, dla którego należy zaznaczyć checkbox przecięcia krzywej z osią Y w punkcie;
kliknij przycisk OK, aby zamknąć okno dialogowe.
Edycję już zbudowanej linii trendu można rozpocząć na trzy sposoby:
użyj komendy Wybrana linia trendu z menu Format, po wybraniu linii trendu;
z menu kontekstowego wybierz polecenie Formatuj linię trendu, które wywołuje się klikając prawym przyciskiem myszy na linię trendu;
poprzez dwukrotne kliknięcie linii trendu.
Na ekranie pojawi się okno dialogowe Formatuj linię trendu (rys. 3), składające się z trzech zakładek: Widok, Typ, Parametry, przy czym zawartość dwóch ostatnich całkowicie pokrywa się z podobnymi zakładkami okna dialogowego Linia trendu (rys. 1-2). ). Na karcie Widok możesz ustawić rodzaj linii, jej kolor i grubość.

Aby usunąć już utworzoną linię trendu, wybierz linię trendu do usunięcia i naciśnij klawisz Delete.
Zaletami rozważanego narzędzia analizy regresji są:
względna łatwość wykreślania linii trendu na wykresach bez tworzenia dla niej tabeli danych;
dość szeroka lista typów proponowanych linii trendu, a lista ta obejmuje najczęściej stosowane typy regresji;
możliwość przewidywania zachowania badanego procesu dla dowolnej (w granicach zdrowego rozsądku) liczby kroków do przodu i do tyłu;
możliwość otrzymania równania linii trendu w formie analitycznej;
możliwość, w razie potrzeby, uzyskania oceny wiarygodności przybliżenia.
Wady obejmują następujące punkty:
konstrukcja linii trendu odbywa się tylko wtedy, gdy istnieje wykres zbudowany na serii danych;
proces generowania serii danych dla badanej cechy na podstawie uzyskanych dla niej równań linii trendu jest nieco zaśmiecony: pożądane równania regresji są aktualizowane przy każdej zmianie wartości oryginalnej serii danych, ale tylko w obszarze wykresu , natomiast szeregi danych utworzone na podstawie trendu starego równania liniowego pozostają niezmienione;
Jeśli w raportach wykresu przestawnego zmienisz widok wykresu lub powiązany raport w formie tabeli przestawnej, istniejące linie trendu nie zostaną zachowane, co oznacza, że przed narysowaniem linii trendu lub innym formatowaniem raportu w formie wykresu przestawnego musisz upewnić się, że układ raportu spełnia Twoje wymagania.
Linie trendu można dodawać do serii danych prezentowanych na wykresach takich jak wykres, histogram, płaskie, nieznormalizowane wykresy warstwowe, wykresy słupkowe, punktowe, bąbelkowe i giełdowe.
Nie można dodawać linii trendu do serii danych na wykresach 3-W, standardowym, radarowym, kołowym i pierścieniowym.
Korzystanie z wbudowanych funkcji programu Excel
Excel udostępnia także narzędzie do analizy regresji umożliwiające wykreślanie linii trendu poza obszarem wykresu. Można w tym celu wykorzystać szereg funkcji arkusza statystycznego, jednak wszystkie pozwalają na budowanie wyłącznie regresji liniowych lub wykładniczych.
Excel ma kilka funkcji do budowania regresji liniowej, w szczególności:
NACHYLENIE i CIĘCIE.
TENDENCJA;
A także kilka funkcji do konstruowania wykładniczej linii trendu, w szczególności:
LGRFPok.
Należy zauważyć, że techniki konstruowania regresji przy użyciu funkcji TREND i WZROST są praktycznie takie same. To samo można powiedzieć o parze funkcji LINEST i LGRFPRIBL. Dla tych czterech funkcji podczas tworzenia tabeli wartości wykorzystywane są funkcje programu Excel takie jak formuły tablicowe, co nieco zaśmieca proces budowania regresji. Zauważamy również, że konstrukcję regresji liniowej naszym zdaniem najłatwiej jest zrealizować za pomocą funkcji SLOPE i INTERCEPT, gdzie pierwsza z nich wyznacza nachylenie regresji liniowej, a druga wyznacza odcinek odcięty przez regresję na osi Y.
Zalety wbudowanego narzędzia funkcyjnego do analizy regresji to:
dość prosty proces tego samego rodzaju tworzenia serii danych o badanej charakterystyce dla wszystkich wbudowanych funkcji statystycznych wyznaczających linie trendu;
standardowa technika konstruowania linii trendu na podstawie wygenerowanych serii danych;
umiejętność przewidywania zachowania badanego procesu dla wymaganej liczby kroków do przodu lub do tyłu.
Do wad należy fakt, że Excel nie ma wbudowanych funkcji do tworzenia innych (z wyjątkiem liniowych i wykładniczych) typów linii trendu. Okoliczność ta często nie pozwala na wybór wystarczająco dokładnego modelu badanego procesu, a także uzyskanie prognoz zbliżonych do rzeczywistości. Dodatkowo przy korzystaniu z funkcji TREND i GROW nie są znane równania linii trendu.
Należy zaznaczyć, że autorzy nie postawili sobie za cel artykułu przedstawienia przebiegu analizy regresji w różnym stopniu kompletności. Jego głównym zadaniem jest pokazanie możliwości pakietu Excel w rozwiązywaniu problemów aproksymacyjnych na konkretnych przykładach; zademonstrować, jakie skuteczne narzędzia ma Excel do budowania regresji i prognozowania; ilustrują, jak stosunkowo łatwo takie problemy może rozwiązać nawet użytkownik, który nie ma głębokiej wiedzy na temat analizy regresji.
Przykłady rozwiązania konkretnych problemów
Rozważ rozwiązanie konkretnych problemów za pomocą wymienionych narzędzi pakietu Excel.
Zadanie 1
Z tabelą danych o zyskach przedsiębiorstwa transportu samochodowego za lata 1995-2002. musisz wykonać następujące czynności.
Zbuduj wykres.
Dodaj do wykresu linie trendu liniowego i wielomianowego (kwadratowego i sześciennego).
Korzystając z równań linii trendu, uzyskaj dane tabelaryczne dotyczące zysku przedsiębiorstwa dla każdej linii trendu za lata 1995-2004.
Sporządź prognozę zysków przedsiębiorstwa na lata 2003 i 2004.
Rozwiązanie problemu

W obszarze komórek A4:C11 arkusza Excel wchodzimy do arkusza pokazanego na rys. 4.
Po wybraniu zakresu komórek B4:C11 budujemy wykres.
Aktywujemy skonstruowany wykres i metodą opisaną powyżej, po wybraniu rodzaju linii trendu w oknie dialogowym Linia trendu (patrz rys. 1), dodajemy do wykresu naprzemiennie linie trendu liniowego, kwadratowego i sześciennego. W tym samym oknie dialogowym należy otworzyć zakładkę Parametry (patrz rys. 2), w polu Nazwa krzywej aproksymującej (wygładzanej) wpisać nazwę trendu, który ma zostać dodany, a w polu Prognoza do przodu na: okresy ustawić wartość 2, gdyż planuje się sporządzenie prognozy zysków na dwa lata do przodu. Aby w obszarze wykresu wyświetlić równanie regresji oraz wartość wiarygodności aproksymacji R2, należy zaznaczyć pola wyboru Pokaż równanie na ekranie i umieścić na wykresie wartość wiarygodności aproksymacji (R^2). Dla lepszej percepcji wizualnej zmieniamy rodzaj, kolor i grubość kreślonych linii trendu, do czego służy zakładka Widok okna dialogowego Format linii trendu (patrz rys. 3). Powstały wykres z dodanymi liniami trendu pokazano na rys. 2. 5.
Uzyskanie danych tabelarycznych o zysku przedsiębiorstwa dla każdej linii trendu za lata 1995-2004. Skorzystajmy z równań linii trendu przedstawionych na ryc. 5. W tym celu w komórkach zakresu D3:F3 należy wpisać informację tekstową o rodzaju wybranej linii trendu: Trend liniowy, Trend kwadratowy, Trend sześcienny. Następnie wpisz formułę regresji liniowej w komórce D4 i korzystając ze znacznika wypełnienia, skopiuj tę formułę z odniesieniami względnymi do zakresu komórek D5:D13. Należy zauważyć, że każda komórka posiadająca formułę regresji liniowej z zakresu komórek D4:D13 ma jako argument odpowiadającą komórkę z zakresu A4:A13. Podobnie w przypadku regresji kwadratowej wypełniany jest zakres komórek E4:E13, a w przypadku regresji sześciennej — zakres komórek F4:F13. W związku z tym sporządzono prognozę zysku przedsiębiorstwa na lata 2003 i 2004. z trzema trendami. Wynikową tabelę wartości pokazano na ryc. 6.


Zadanie 2
Zbuduj wykres.
Dodaj do wykresu linie trendu logarytmicznego, wykładniczego i wykładniczego.
Wyprowadź równania otrzymanych linii trendu, a także wartości wiarygodności aproksymacji R2 dla każdej z nich.
Korzystając z równań linii trendu, uzyskaj dane tabelaryczne dotyczące zysku przedsiębiorstwa dla każdej linii trendu za lata 1995-2002.
Korzystając z tych linii trendu, sporządź prognozę zysków firmy na lata 2003 i 2004.
Rozwiązanie problemu
Kierując się metodologią podaną przy rozwiązaniu zadania 1, otrzymujemy diagram z dodanymi liniami trendu logarytmicznego, wykładniczego i wykładniczego (rys. 7). Następnie, korzystając z otrzymanych równań linii trendu, wypełniamy tabelę wartości zysku przedsiębiorstwa, zawierającą przewidywane wartości na lata 2003 i 2004. (ryc. 8).


Na ryc. 5 i rys. widać, że model z trendem logarytmicznym odpowiada najniższej wartości wiarygodności aproksymacji
R2 = 0,8659
Największe wartości R2 odpowiadają modelom o trendzie wielomianowym: kwadratowym (R2 = 0,9263) i sześciennym (R2 = 0,933).
Zadanie 3
Mając tabelę danych o zyskach przedsiębiorstwa transportu samochodowego za lata 1995-2002, podaną w zadaniu 1, należy wykonać następujące kroki.
Uzyskaj serie danych dla liniowych i wykładniczych linii trendu, korzystając z funkcji TREND i GROW.
Korzystając z funkcji TREND i WZROST, sporządź prognozę zysków przedsiębiorstwa na lata 2003 i 2004.
Dla danych początkowych i otrzymanych serii danych skonstruuj diagram.
Rozwiązanie problemu
Skorzystajmy z karty pracy zadania 1 (patrz rys. 4). Zacznijmy od funkcji TREND:
wybierz zakres komórek D4:D11, który należy wypełnić wartościami funkcji TREND odpowiadającymi znanym danym o zysku przedsiębiorstwa;
wywołaj polecenie Funkcja z menu Wstaw. W wyświetlonym oknie dialogowym Kreator funkcji wybierz funkcję TREND z kategorii Statystyka, a następnie kliknij przycisk OK. Tę samą operację można wykonać naciskając przycisk (funkcja Wstaw) znajdujący się na standardowym pasku narzędzi.
W wyświetlonym oknie dialogowym Argumenty funkcji wprowadź zakres komórek C4:C11 w polu Znane_wartości_y; w polu Znane_wartości_x - zakres komórek B4:B11;
aby wprowadzona formuła stała się formułą tablicową, użyj kombinacji klawiszy + + .
Formuła, którą wpisaliśmy w pasku formuły, będzie wyglądać następująco: =(TREND(C4:C11;B4:B11)).
W rezultacie zakres komórek D4:D11 zostaje wypełniony odpowiednimi wartościami funkcji TREND (rys. 9).

Sporządzenie prognozy zysków spółki na lata 2003 i 2004. niezbędny:
wybierz zakres komórek D12:D13, w którym zostaną wprowadzone wartości przewidywane funkcją TREND.
wywołaj funkcję TREND i w wyświetlonym oknie Argumenty funkcji wpisz w polu Znane_wartości_y - zakres komórek C4:C11; w polu Znane_wartości_x - zakres komórek B4:B11; oraz w polu Nowe_wartości_x - zakres komórek B12:B13.
zamień tę formułę w formułę tablicową za pomocą skrótu klawiaturowego Ctrl + Shift + Enter.
Wprowadzona formuła będzie wyglądać następująco: =(TREND(C4:C11;B4:B11;B12:B13)), a zakres komórek D12:D13 zostanie wypełniony przewidywanymi wartościami funkcji TREND (patrz rys. 9).
Podobnie seria danych jest wypełniana za pomocą funkcji WZROST, która służy do analizy zależności nieliniowych i działa dokładnie tak samo, jak jej liniowy odpowiednik TREND.
Rysunek 10 przedstawia tabelę w trybie wyświetlania formuły.


Dla danych początkowych i otrzymanych serii danych schemat pokazany na rys. jedenaście.
Zadanie 4
Mając tabelę danych o przyjęciu wniosków o usługi przez służbę dyspozytorską przedsiębiorstwa transportu samochodowego za okres od 1 do 11 dnia bieżącego miesiąca należy wykonać następujące czynności.
Uzyskaj serie danych do regresji liniowej: korzystając z funkcji SLOPE i INTERCEPT; za pomocą funkcji REGLINP.
Pobierz serię danych dla regresji wykładniczej za pomocą funkcji LYFFPRIB.
Korzystając z powyższych funkcji, utwórz prognozę wpływu wniosków do działu spedycyjnego na okres od 12 do 14 dnia bieżącego miesiąca.
Dla oryginalnej i otrzymanej serii danych skonstruuj diagram.
Rozwiązanie problemu
Należy zauważyć, że w przeciwieństwie do funkcji TREND i GROW żadna z funkcji wymienionych powyżej (NACHYLENIE, PRZECHWYCZENIE, REGLINP, LGRFPRIB) nie jest regresją. Funkcje te pełnią jedynie rolę pomocniczą, wyznaczając niezbędne parametry regresji.
W przypadku regresji liniowych i wykładniczych budowanych za pomocą funkcji SLOPE, INTERCEPT, LINEST, LGRFINB zawsze znany jest wygląd ich równań, w przeciwieństwie do regresji liniowych i wykładniczych odpowiadających funkcjom TREND i GROWTH.
1 . Zbudujmy regresję liniową, która ma równanie:
y=mx+b
przy pomocy funkcji SLOPE i INTERCEPT, przy czym nachylenie regresji m wyznacza funkcja SLOPE, a człon stały b - funkcją INTERCEPT.
W tym celu wykonujemy następujące czynności:
wprowadź tabelę źródłową w zakresie komórek A4:B14;
wartość parametru m zostanie określona w komórce C19. Wybierz z kategorii Statystyka funkcję Nachylenie; wpisz zakres komórek B4:B14 w polu znane_wartości_y oraz zakres komórek A4:A14 w polu znane_wartości_x. Formuła zostanie wpisana do komórki C19: =SLOPE(B4:B14;A4:A14);
analogicznie ustala się wartość parametru b w komórce D19. A jego zawartość będzie wyglądać następująco: = INTERCEPT(B4:B14;A4:A14). Zatem wartości parametrów m i b, niezbędne do skonstruowania regresji liniowej, zostaną zapisane odpowiednio w komórkach C19, D19;
następnie wpisujemy wzór regresji liniowej w komórce C4 w postaci: = $ C * A4 + $ D. W tej formule komórki C19 i D19 zapisywane są z odwołaniami bezwzględnymi (adres komórki nie powinien zmieniać się przy ewentualnym kopiowaniu). Znak odniesienia bezwzględnego $ można wpisać z klawiatury lub przy pomocy klawisza F4, po umieszczeniu kursora na adresie komórki. Używając uchwytu wypełniania, skopiuj tę formułę do zakresu komórek C4:C17. Otrzymujemy żądaną serię danych (ryc. 12). Z uwagi na to, że liczba żądań jest liczbą całkowitą, należy w zakładce Liczba okna Format komórki ustawić format liczb z liczbą miejsc po przecinku na 0.
2 . Zbudujmy teraz regresję liniową określoną równaniem:
y=mx+b
za pomocą funkcji REGLINP.
Dla tego:
wprowadź funkcję REGLINP jako formułę tablicową w zakresie komórek C20:D20: =(LINEST(B4:B14;A4:A14)). W rezultacie otrzymujemy wartość parametru m w komórce C20 i wartość parametru b w komórce D20;
wpisz formułę w komórce D4: =$C*A4+$D;
skopiuj tę formułę za pomocą znacznika wypełnienia do zakresu komórek D4:D17 i uzyskaj żądaną serię danych.
3 . Budujemy regresję wykładniczą, która ma równanie:
za pomocą funkcji LGRFPRIBL wykonuje się to analogicznie:
w zakresie komórek C21:D21 wprowadź funkcję LGRFPRIBL jako formułę tablicową: =( LGRFPRIBL (B4:B14;A4:A14)). W tym przypadku wartość parametru m zostanie określona w komórce C21, a wartość parametru b zostanie określona w komórce D21;
formułę wpisuje się do komórki E4: =$D*$C^A4;
za pomocą znacznika wypełnienia formuła ta jest kopiowana do zakresu komórek E4:E17, gdzie będzie zlokalizowany szereg danych dla regresji wykładniczej (patrz rys. 12).

Na ryc. 13 pokazuje tabelę, w której możemy zobaczyć funkcje, których używamy z niezbędnymi zakresami komórek, a także formułami.
Wartość R 2 zwany współczynnik determinacji.
Zadaniem konstrukcji zależności regresyjnej jest znalezienie wektora współczynników m modelu (1), przy którym współczynnik R przyjmuje wartość maksymalną.
Aby ocenić istotność R, stosuje się test F Fishera, obliczany według wzoru

Gdzie N- wielkość próby (liczba eksperymentów);
k jest liczbą współczynników modelu.
Jeśli F przekracza pewną wartość krytyczną dla danych N I k a przyjętym poziomem ufności, wówczas wartość R uważa się za znaczącą. Tabele wartości krytycznych F podano w podręcznikach dotyczących statystyki matematycznej.
Zatem o istotności R decyduje nie tylko jego wartość, ale także stosunek liczby eksperymentów do liczby współczynników (parametrów) modelu. Rzeczywiście, współczynnik korelacji dla n=2 dla prostego modelu liniowego wynosi 1 (przez 2 punkty na płaszczyźnie zawsze można poprowadzić pojedynczą linię prostą). Jeśli jednak danymi eksperymentalnymi są zmienne losowe, takiej wartości R należy ufać z dużą ostrożnością. Zwykle, aby uzyskać znaczący R i wiarygodną regresję, dąży się do tego, aby liczba eksperymentów znacznie przekraczała liczbę współczynników modelu (n>k).
Aby zbudować model regresji liniowej, należy:
1) przygotować listę n wierszy i m kolumn zawierających dane eksperymentalne (kolumna zawierająca wartość wyjściową Y musi być pierwszy lub ostatni na liście); weźmy np. dane z poprzedniego zadania, dodając kolumnę o nazwie „numer okresu”, numerując numery okresów od 1 do 12. (będą to wartości X)
2) przejdź do menu Dane/Analiza danych/Regresja

Jeżeli w menu „Narzędzia” brakuje pozycji „Analiza danych”, należy przejść do pozycji „Dodatki” w tym samym menu i zaznaczyć pole „Pakiet analityczny”.
3) w oknie dialogowym „Regresja” ustaw:
interwał wejściowy Y;
interwał wejściowy X;
przedział wyjściowy - lewa górna komórka przedziału, w którym zostaną umieszczone wyniki obliczeń (zaleca się umieszczenie go na nowym arkuszu);

4) kliknij „OK” i przeanalizuj wyniki.
Jeśli jakaś wielkość fizyczna zależy od innej wielkości, wówczas zależność tę można zbadać, mierząc y przy różnych wartościach x. W wyniku pomiarów uzyskuje się szereg wartości:
x 1 , x 2 , ..., x i , ... , x n ;
y 1 , y 2 , ..., y ja , ... , y n .
Na podstawie danych takiego eksperymentu można wykreślić zależność y = ƒ(x). Otrzymana krzywa pozwala ocenić postać funkcji ƒ(x). Jednak stałe współczynniki, które wchodzą w skład tej funkcji, pozostają nieznane. Można je wyznaczyć metodą najmniejszych kwadratów. Punkty doświadczalne z reguły nie leżą dokładnie na krzywej. Metoda najmniejszych kwadratów wymaga, aby suma kwadratów odchyleń punktów doświadczalnych od krzywej, tj. 2 był najmniejszy.
W praktyce metodę tę najczęściej (i najprościej) stosuje się w przypadku zależności liniowej, tj. Gdy
y=kx Lub y = a + bx.
Zależność liniowa jest bardzo rozpowszechniona w fizyce. A nawet gdy zależność jest nieliniowa, to zazwyczaj starają się zbudować wykres tak, aby otrzymać linię prostą. Przykładowo, jeśli przyjmiemy, że współczynnik załamania światła szkła n jest powiązany z długością fali λ fali świetlnej zależnością n = a + b/λ 2 , to na wykresie wykreślana jest zależność n od λ -2 .
Rozważ zależność y=kx(prosta przechodząca przez początek). Skomponujmy wartość φ z sumy kwadratów odchyleń naszych punktów od prostej
Wartość φ jest zawsze dodatnia i okazuje się tym mniejsza, im bliżej prostej leżą nasze punkty. Metoda najmniejszych kwadratów stwierdza, że dla k należy wybrać taką wartość, przy której φ ma minimum
![]()
Lub
(19)
Obliczenia pokazują, że błąd średniokwadratowy przy określaniu wartości k jest równy
 , (20)
, (20)
gdzie n jest liczbą wymiarów.
Rozważmy teraz nieco trudniejszy przypadek, gdy punkty muszą spełniać wzór y = a + bx(linia prosta nie przechodząca przez początek układu współrzędnych).
Zadanie polega na znalezieniu najlepszych wartości a i b z podanego zbioru wartości x i, y i.
Ponownie tworzymy postać kwadratową φ równą sumie kwadratów odchyleń punktów x i , y i od linii prostej
![]()
i znajdź wartości aib, dla których φ ma minimum
![]() ;
;
![]() .
.
Daje wspólne rozwiązanie tych równań
![]() (21)
(21)
Błędy średniokwadratowe wyznaczania a i b są równe
 (23)
(23)
 . (24)
. (24)
Opracowując wyniki pomiarów tą metodą, wygodnie jest podsumować wszystkie dane w tabeli, w której wstępnie wyliczone są wszystkie wielkości zawarte we wzorach (19)(24). Formy tych tabel pokazano w poniższych przykładach.
Przykład 1 Badano podstawowe równanie dynamiki ruchu obrotowego ε = M/J (prosta przechodząca przez początek układu współrzędnych). Dla różnych wartości momentu M mierzono przyspieszenie kątowe ε pewnego ciała. Należy wyznaczyć moment bezwładności tego ciała. Wyniki pomiarów momentu siły i przyspieszenia kątowego zestawiono w kolumnach drugiej i trzeciej tabele 5.
Tabela 5
| N | M, Nm | ε, s-1 | M2 | M ε | ε - kM | (ε - kM) 2 |
| 1 | 1.44 | 0.52 | 2.0736 | 0.7488 | 0.039432 | 0.001555 |
| 2 | 3.12 | 1.06 | 9.7344 | 3.3072 | 0.018768 | 0.000352 |
| 3 | 4.59 | 1.45 | 21.0681 | 6.6555 | -0.08181 | 0.006693 |
| 4 | 5.90 | 1.92 | 34.81 | 11.328 | -0.049 | 0.002401 |
| 5 | 7.45 | 2.56 | 55.5025 | 19.072 | 0.073725 | 0.005435 |
| ∑ | | | 123.1886 | 41.1115 | | 0.016436 |
Ze wzoru (19) określamy:
![]() .
.
Aby wyznaczyć błąd średniokwadratowy, korzystamy ze wzoru (20)
0.005775kg-1 · M -2 .
Według wzoru (18) mamy

SJ = (2,996 0,005775)/0,3337 = 0,05185 kg·m2.
Mając niezawodność P = 0,95, zgodnie z tabelą współczynników Studenta dla n = 5, znajdujemy t = 2,78 i wyznaczamy błąd bezwzględny ΔJ = 2,78 0,05185 = 0,1441 ≈ 0,2 kg·m2.
Wyniki zapisujemy w postaci:
J = (3,0 ± 0,2) kg·m2;
Przykład 2 Współczynnik temperaturowy oporu metalu obliczamy metodą najmniejszych kwadratów. Opór zależy od temperatury zgodnie z prawem liniowym
R t \u003d R 0 (1 + α t °) \u003d R 0 + R 0 α t °.
Wolny człon określa rezystancję R 0 w temperaturze 0 ° C, a współczynnik kątowy jest iloczynem współczynnika temperaturowego α i rezystancji R 0 .
Wyniki pomiarów i obliczeń podano w tabeli ( patrz tabela 6).
Tabela 6
| N | t°, s | r, Och | t-¯t | (t-¯t) 2 | (t-¯t)r | r-bt-a | (r - bt - a) 2,10 -6 |
| 1 | 23 | 1.242 | -62.8333 | 3948.028 | -78.039 | 0.007673 | 58.8722 |
| 2 | 59 | 1.326 | -26.8333 | 720.0278 | -35.581 | -0.00353 | 12.4959 |
| 3 | 84 | 1.386 | -1.83333 | 3.361111 | -2.541 | -0.00965 | 93.1506 |
| 4 | 96 | 1.417 | 10.16667 | 103.3611 | 14.40617 | -0.01039 | 107.898 |
| 5 | 120 | 1.512 | 34.16667 | 1167.361 | 51.66 | 0.021141 | 446.932 |
| 6 | 133 | 1.520 | 47.16667 | 2224.694 | 71.69333 | -0.00524 | 27.4556 |
| ∑ | 515 | 8.403 | | 8166.833 | 21.5985 | | 746.804 |
| ∑/n | 85.83333 | 1.4005 | | | | | |
Za pomocą wzorów (21), (22) określamy
R 0 = ¯ R- α R 0 ¯ t = 1,4005 - 0,002645 85,83333 = 1,1735 Om.
Znajdźmy błąd w definicji α. Ponieważ , to według wzoru (18) mamy:
 .
.
Korzystając ze wzorów (23), (24) mamy

 ;
;
0.014126 Om.
Mając niezawodność P = 0,95, zgodnie z tabelą współczynników Studenta dla n = 6, znajdujemy t = 2,57 i wyznaczamy błąd bezwzględny Δα = 2,57 0,000132 = 0,000338 stopień -1.
α = (23 ± 4) 10 -4 grad-1 przy P = 0,95.
Przykład 3 Wymagane jest określenie promienia krzywizny soczewki na podstawie pierścieni Newtona. Zmierzono promienie pierścieni Newtona r m i wyznaczono numery tych pierścieni m. Promienie pierścieni Newtona są powiązane z promieniem krzywizny soczewki R i liczbą pierścieni za pomocą równania
r 2 m = mλR - 2d 0 R,
gdzie d 0 grubość szczeliny między soczewką a płaskorównoległą płytką (lub odkształcenie soczewki),
λ jest długością fali padającego światła.
λ = (600 ± 6) nm;
r 2 m = y;
m = x;
λR = b;
-2d 0 R = a,
wtedy równanie przyjmie postać y = a + bx.
.Wyniki pomiarów i obliczeń są wpisywane tabela 7.
Tabela 7
| N | x = m | y \u003d r 2, 10 -2 mm 2 | m-¯m | (m-¯m) 2 | (m-¯m) r | y-bx-a, 10-4 | (y - bx - a) 2, 10 -6 |
| 1 | 1 | 6.101 | -2.5 | 6.25 | -0.152525 | 12.01 | 1.44229 |
| 2 | 2 | 11.834 | -1.5 | 2.25 | -0.17751 | -9.6 | 0.930766 |
| 3 | 3 | 17.808 | -0.5 | 0.25 | -0.08904 | -7.2 | 0.519086 |
| 4 | 4 | 23.814 | 0.5 | 0.25 | 0.11907 | -1.6 | 0.0243955 |
| 5 | 5 | 29.812 | 1.5 | 2.25 | 0.44718 | 3.28 | 0.107646 |
| 6 | 6 | 35.760 | 2.5 | 6.25 | 0.894 | 3.12 | 0.0975819 |
| ∑ | 21 | 125.129 | | 17.5 | 1.041175 | | 3.12176 |
| ∑/n | 3.5 | 20.8548333 | | | | | |
Wybór rodzaju funkcji regresji, tj. rodzaj rozważanego modelu zależności Y od X (lub X od Y), np. model liniowy y x = a + bx, konieczne jest określenie konkretnych wartości współczynników modelu.
Dla różnych wartości a i b można skonstruować nieskończoną liczbę zależności postaci y x =a+bx, czyli na płaszczyźnie współrzędnych istnieje nieskończona liczba prostych, ale potrzebujemy takiej zależności, że najlepiej odpowiada obserwowanym wartościom. Zatem problem sprowadza się do wyboru najlepszych współczynników.
Szukamy funkcji liniowej a + bx, bazując tylko na pewnej liczbie dostępnych obserwacji. Aby znaleźć funkcję najlepiej dopasowaną do obserwowanych wartości, stosujemy metodę najmniejszych kwadratów.
Oznacz: Y i - wartość obliczona z równania Y i =a+bx i . y i - wartość zmierzona, ε i =y i -Y i - różnica pomiędzy wartością zmierzoną i obliczoną, ε i =y i -a-bx i .
Metoda najmniejszych kwadratów wymaga, aby ε i, różnica między zmierzonym y i a wartościami Y i obliczonymi z równania, była minimalna. Dlatego znajdujemy współczynniki aib tak, aby suma kwadratów odchyleń zaobserwowanych wartości od wartości na prostej linii regresji była najmniejsza:
Badając tę funkcję argumentów a i za pomocą pochodnych do ekstremum można wykazać, że funkcja ta przyjmuje wartość minimalną, jeśli współczynniki a i b są rozwiązaniami układu:
 (2)
(2)
Jeśli podzielimy obie strony równań normalnych przez n, otrzymamy:

Jeśli się uwzględni  (3)
(3)
Dostawać  stąd, zastępując wartość a w pierwszym równaniu, otrzymujemy:
stąd, zastępując wartość a w pierwszym równaniu, otrzymujemy:

W tym przypadku b nazywa się współczynnikiem regresji; a nazywa się wolnym członkiem równania regresji i oblicza się według wzoru:
Powstała linia prosta jest oszacowaniem teoretycznej linii regresji. Mamy:
Więc, ![]() jest równaniem regresji liniowej.
jest równaniem regresji liniowej.
Regresja może być bezpośrednia (b>0) i odwrotna (b Przykład 1. Wyniki pomiaru wartości X i Y podano w tabeli:
| x ja | -2 | 0 | 1 | 2 | 4 |
| tak, ja | 0.5 | 1 | 1.5 | 2 | 3 |
Zakładając, że pomiędzy X i Y istnieje liniowa zależność y=a+bx, wyznacz współczynniki a i b metodą najmniejszych kwadratów.
Rozwiązanie. Tutaj n=5
x i =-2+0+1+2+4=5;
x i 2 =4+0+1+4+16=25
x i y ja =-2 0,5+0 1+1 1,5+2 2+4 3=16,5
y i =0,5+1+1,5+2+3=8
a układ normalny (2) ma postać ![]()
Rozwiązując ten układ otrzymujemy: b=0,425, a=1,175. Zatem y=1,175+0,425x.
Przykład 2. Próba składa się z 10 obserwacji wskaźników ekonomicznych (X) i (Y).
| x ja | 180 | 172 | 173 | 169 | 175 | 170 | 179 | 170 | 167 | 174 |
| tak, ja | 186 | 180 | 176 | 171 | 182 | 166 | 182 | 172 | 169 | 177 |
Wymagane jest znalezienie przykładowego równania regresji Y na X. Skonstruuj przykładową linię regresji Y na X.
Rozwiązanie. 1. Posortujmy dane według wartości x i oraz y i . Otrzymujemy nową tabelę:
| x ja | 167 | 169 | 170 | 170 | 172 | 173 | 174 | 175 | 179 | 180 |
| tak, ja | 169 | 171 | 166 | 172 | 180 | 176 | 177 | 182 | 182 | 186 |
Aby uprościć obliczenia, stworzymy tabelę obliczeniową, w której wprowadzimy niezbędne wartości liczbowe.
| x ja | tak, ja | x i 2 | x i y i |
| 167 | 169 | 27889 | 28223 |
| 169 | 171 | 28561 | 28899 |
| 170 | 166 | 28900 | 28220 |
| 170 | 172 | 28900 | 29240 |
| 172 | 180 | 29584 | 30960 |
| 173 | 176 | 29929 | 30448 |
| 174 | 177 | 30276 | 30798 |
| 175 | 182 | 30625 | 31850 |
| 179 | 182 | 32041 | 32578 |
| 180 | 186 | 32400 | 33480 |
| ∑x i =1729 | ∑y i =1761 | ∑x i 2 299105 | ∑x i y i =304696 |
| x=172,9 | y=176,1 | x i2 =29910,5 | xy=30469,6 |
Zgodnie ze wzorem (4) obliczamy współczynnik regresji
i według wzoru (5)
Zatem przykładowe równanie regresji wygląda następująco: y=-59,34+1,3804x.
Narysujmy punkty (x i ; y i) na płaszczyźnie współrzędnych i zaznaczmy linię regresji.

Ryc. 4
Rysunek 4 pokazuje, jak zaobserwowane wartości są umiejscowione względem linii regresji. Aby numerycznie oszacować odchylenia y i od Y i , gdzie y i to wartości obserwowane, a Y i to wartości wyznaczone metodą regresji, zrobimy tabelę:
| x ja | tak, ja | Y ja | Y-y ja |
| 167 | 169 | 168.055 | -0.945 |
| 169 | 171 | 170.778 | -0.222 |
| 170 | 166 | 172.140 | 6.140 |
| 170 | 172 | 172.140 | 0.140 |
| 172 | 180 | 174.863 | -5.137 |
| 173 | 176 | 176.225 | 0.225 |
| 174 | 177 | 177.587 | 0.587 |
| 175 | 182 | 178.949 | -3.051 |
| 179 | 182 | 184.395 | 2.395 |
| 180 | 186 | 185.757 | -0.243 |
Wartości Y i są obliczane zgodnie z równaniem regresji.
Zauważalne odchylenie niektórych zaobserwowanych wartości od linii regresji tłumaczy się małą liczbą obserwacji. Badając stopień liniowej zależności Y od X, bierze się pod uwagę liczbę obserwacji. O sile zależności decyduje wartość współczynnika korelacji.
Problem polega na znalezieniu współczynników zależności liniowej dla których spełnia się funkcja dwóch zmiennych A I B przyjmuje najmniejszą wartość. To znaczy, biorąc pod uwagę dane A I B suma kwadratów odchyleń danych eksperymentalnych od znalezionej prostej będzie najmniejsza. Na tym polega cały sens metody najmniejszych kwadratów.
Zatem rozwiązanie przykładu sprowadza się do znalezienia ekstremum funkcji dwóch zmiennych.
Wyprowadzenie wzorów na znalezienie współczynników. Układ dwóch równań z dwiema niewiadomymi jest kompilowany i rozwiązywany. Znajdowanie pochodnych cząstkowych funkcji ![]() przez zmienne A I B, przyrównujemy te pochodne do zera.
przez zmienne A I B, przyrównujemy te pochodne do zera.

Powstały układ równań rozwiązujemy dowolną metodą (na przykład metodą podstawieniową lub metodą Cramera) i uzyskujemy wzory na znalezienie współczynników metodą najmniejszych kwadratów (LSM). 
Z danymi A I B funkcjonować ![]() przyjmuje najmniejszą wartość.
przyjmuje najmniejszą wartość.
To cała metoda najmniejszych kwadratów. Wzór na znalezienie parametru A zawiera sumy , , i parametr N- ilość danych eksperymentalnych. Wartości tych sum zaleca się obliczać osobno. Współczynnik B znalezione po obliczeniach A.
Głównym obszarem zastosowania takich wielomianów jest przetwarzanie danych eksperymentalnych (konstruowanie wzorów empirycznych). Faktem jest, że wielomian interpolacyjny zbudowany z wartości funkcji uzyskanych za pomocą eksperymentu będzie pod silnym wpływem „szumu eksperymentalnego”, ponadto podczas interpolacji węzły interpolacji nie mogą się powtarzać, tj. nie można wykorzystywać wyników powtarzanych eksperymentów w tych samych warunkach. Wielomian średniokwadratowy wygładza szum i umożliwia wykorzystanie wyników wielu eksperymentów.
Całkowanie i różniczkowanie numeryczne. Przykład.
Całkowanie numeryczne- obliczenie wartości całki oznaczonej (z reguły przybliżonej). Całkę numeryczną rozumiemy jako zbiór metod numerycznych służących do znajdowania wartości określonej całki.
Różniczkowanie numeryczne– zestaw metod obliczania wartości pochodnej funkcji dyskretnie danej.
Integracja
Sformułowanie problemu. Matematyczne przedstawienie problemu: konieczne jest znalezienie wartości pewnej całki
gdzie a, b są skończone, f(x) jest ciągłe na [а, b].
Przy rozwiązywaniu problemów praktycznych często zdarza się, że całka jest niewygodna lub niemożliwa do potraktowania analitycznego: nie można jej wyrazić w funkcjach elementarnych, całkę można podać w postaci tabeli itp. W takich przypadkach stosuje się metody całkowania numerycznego używany. Metody całkowania numerycznego polegają na zastąpieniu pola trapezu krzywoliniowego skończoną sumą obszarów o prostszych kształtach geometrycznych, które można dokładnie obliczyć. W tym sensie mówi się o zastosowaniu wzorów kwadraturowych.
Większość metod wykorzystuje reprezentację całki jako sumy skończonej (wzór kwadraturowy):
Wzory kwadraturowe opierają się na idei zastąpienia wykresu całki na przedziale całkowania funkcjami o prostszej postaci, które można łatwo zintegrować analitycznie, a co za tym idzie, łatwo obliczyć. Najprostsze zadanie konstruowania wzorów kwadraturowych realizuje się dla wielomianowych modeli matematycznych.
Można wyróżnić trzy grupy metod:
1. Metoda z podziałem odcinka całkowania na równe przedziały. Podziału na przedziały dokonuje się z góry, zazwyczaj wybiera się przedziały równe (aby ułatwić obliczenie funkcji na końcach przedziałów). Oblicz pola i zsumuj je (metody prostokątów, trapezu, Simpsona).
2. Metody podziału odcinka całkowania za pomocą punktów specjalnych (metoda Gaussa).
3. Obliczanie całek za pomocą liczb losowych (metoda Monte Carlo).
Metoda prostokątna. Niech funkcja (rysunek) będzie całkowana numerycznie na odcinku . Dzielimy odcinek na N równych odcinków. Pole każdego z N trapezów krzywoliniowych można zastąpić polem prostokąta.

Szerokość wszystkich prostokątów jest taka sama i równa:
![]()
Jako wybór wysokości prostokątów można wybrać wartość funkcji znajdującej się po lewej stronie. W tym przypadku wysokość pierwszego prostokąta będzie wynosić f(a), drugiego będzie wynosić f(x 1),…, N-f(N-1).
Jeśli jako wybór wysokości prostokąta przyjmiemy wartość funkcji na prawym brzegu, to w tym przypadku wysokość pierwszego prostokąta będzie wynosić f (x 1), drugiego - f (x 2), . .., N - f (x N).
Jak widać, w tym przypadku jeden ze wzorów daje przybliżenie całki z nadmiarem, a drugi z niedoborem. Jest inny sposób - wykorzystać do przybliżenia wartość funkcji w środku segmentu całkującego:
Oszacowanie błędu bezwzględnego metody prostokątów (środek)
Oszacowanie błędu bezwzględnego metod lewego i prawego prostokąta.
Przykład. Oblicz dla całego przedziału i podziel go na cztery części
Rozwiązanie. Analityczne obliczenie tej całki daje I=arctg(1) –arctg(0)=0,7853981634. W naszym przypadku:
1) h = 1; xo = 0; x1 = 1;
2) h = 0,25 (1/4); x0 = 0; x1 = 0,25; x2 = 0,5; x3 = 0,75; x4 = 1;
Obliczamy metodą lewych prostokątów:
![]()
Obliczamy metodą prostokątów prostokątnych:
![]()
Oblicz metodą średnich prostokątów:
![]()

Metoda trapezowa. Użycie do interpolacji wielomianu pierwszego stopnia (prosta poprowadzona przez dwa punkty) prowadzi do wzoru na trapez. Końce segmentu całkowania traktowane są jako węzły interpolacji. W ten sposób trapez krzywoliniowy zastępuje się zwykłym trapezem, którego powierzchnię można znaleźć jako iloczyn połowy sumy podstaw i wysokości

![]() W przypadku N odcinków całkowania dla wszystkich węzłów, z wyjątkiem skrajnych punktów odcinka, wartość funkcji zostanie uwzględniona w sumie dwukrotnie (ponieważ sąsiednie trapezy mają jeden wspólny bok)
W przypadku N odcinków całkowania dla wszystkich węzłów, z wyjątkiem skrajnych punktów odcinka, wartość funkcji zostanie uwzględniona w sumie dwukrotnie (ponieważ sąsiednie trapezy mają jeden wspólny bok)
![]()
Wzór trapezu można otrzymać, biorąc połowę sumy wzorów prostokątnych wzdłuż prawej i lewej krawędzi odcinka:
Sprawdzenie stabilności rozwiązania. Z reguły im krótsza jest długość każdego interwału, tj. im większa liczba tych przedziałów, tym mniejsza różnica między przybliżonymi i dokładnymi wartościami całki. Dotyczy to większości funkcji. W metodzie trapezowej błąd w obliczeniu całki ϭ jest w przybliżeniu proporcjonalny do kwadratu kroku całkowania (ϭ ~ h 2). Zatem, aby obliczyć całkę określonej funkcji w granicach a, b, konieczne jest podziel odcinek na N 0 odcinków i znajdź sumę pól trapezu. Następnie musisz zwiększyć liczbę przedziałów N 1, ponownie obliczyć sumę trapezu i porównać wynikową wartość z poprzednim wynikiem. Należy to powtarzać aż do osiągnięcia (N i) określonej dokładności wyniku (kryterium zbieżności).
W przypadku metod prostokątnych i trapezowych zwykle w każdym kroku iteracji liczba przedziałów zwiększa się 2-krotnie (N i +1 =2N i).
Kryterium zbieżności:
Główną zaletą reguły trapezu jest jej prostota. Jeśli jednak integracja wymaga dużej precyzji, metoda ta może wymagać zbyt wielu iteracji.
Błąd bezwzględny metody trapezowej oceniane jako
.
Przykład. Oblicz całkę w przybliżeniu oznaczoną, korzystając ze wzoru na trapez.
a) Podział segmentu integracyjnego na 3 części.
b) Podział segmentu integracji na 5 części.
Rozwiązanie:
a) Warunkowo segment integracji należy podzielić na 3 części, tj.
Oblicz długość każdego odcinka przegrody: ![]() .
.
W ten sposób ogólny wzór trapezów zostaje zredukowany do przyjemnego rozmiaru:

Wreszcie:
Przypominam, że otrzymana wartość jest przybliżoną wartością powierzchni.
b) Segment integracji dzielimy na 5 równych części, tj. . zwiększając liczbę segmentów zwiększamy dokładność obliczeń.
Jeżeli , to wzór na trapez przyjmuje postać:
Znajdźmy krok partycjonowania: ![]() , to znaczy długość każdego segmentu pośredniego wynosi 0,6.
, to znaczy długość każdego segmentu pośredniego wynosi 0,6.
Po zakończeniu zadania wygodnie jest sporządzić wszystkie obliczenia za pomocą tabeli obliczeń:
W pierwszym wierszu piszemy „licznik”
W rezultacie: 
Cóż, naprawdę jest wyjaśnienie, i to poważne!
Jeśli dla 3 segmentów przegrody, to dla 5 segmentów. Jeśli weźmiesz jeszcze więcej segmentów => będzie jeszcze dokładniejszy.
Formuła Simpsona. Wzór trapezowy daje wynik silnie zależny od wielkości kroku h, co wpływa na dokładność obliczenia całki oznaczonej, szczególnie w przypadkach, gdy funkcja jest niemonotoniczna. Można założyć wzrost dokładności obliczeń, jeżeli zamiast odcinków prostych zastępujących krzywoliniowe fragmenty wykresu funkcji f(x) zastosujemy np. fragmenty paraboli dane przez trzy sąsiednie punkty wykresu . Podobna interpretacja geometryczna leży u podstaw metody Simpsona służącej do obliczania całki oznaczonej. Cały przedział całkowania a,b dzielimy na N odcinków, długość odcinka również będzie równa h=(b-a)/N.

Wzór Simpsona to:
![]() pozostały termin
pozostały termin
Wraz ze wzrostem długości segmentów dokładność wzoru maleje, dlatego w celu zwiększenia dokładności stosuje się złożony wzór Simpsona. Cały przedział całkowania dzielimy na parzystą liczbę identycznych odcinków N, długość odcinka również będzie równa h=(b-a)/N. Złożony wzór Simpsona to:
We wzorze wyrażenia w nawiasach są sumami wartości odpowiednio całki na końcach nieparzystych i parzystych segmentów wewnętrznych.
Pozostała część wzoru Simpsona jest już proporcjonalna do czwartej potęgi kroku:
![]()
Przykład: Oblicz całkę, korzystając z reguły Simpsona. (Dokładne rozwiązanie - 0,2)


Metoda Gaussa
 Wzór kwadraturowy Gaussa. Podstawową zasadę wzorów kwadraturowych drugiej odmiany widać na rysunku 1.12: należy tak rozmieścić punkty X 0 i X 1 wewnątrz segmentu [ A;B] tak, aby pola „trójkątów” w sumie były równe obszarom „odcinka”. Podczas korzystania ze wzoru Gaussa początkowy segment [ A;B] jest redukowany do przedziału [-1;1] poprzez zmianę zmiennej X NA
Wzór kwadraturowy Gaussa. Podstawową zasadę wzorów kwadraturowych drugiej odmiany widać na rysunku 1.12: należy tak rozmieścić punkty X 0 i X 1 wewnątrz segmentu [ A;B] tak, aby pola „trójkątów” w sumie były równe obszarom „odcinka”. Podczas korzystania ze wzoru Gaussa początkowy segment [ A;B] jest redukowany do przedziału [-1;1] poprzez zmianę zmiennej X NA
0.5∙(B– A)∙T+ 0.5∙(B + A).
Następnie ![]() , Gdzie
, Gdzie ![]() .
.
To podstawienie jest możliwe, jeśli A I B są skończone, oraz funkcja F(X) jest ciągły w [ A;B] Wzór Gaussa na N zwrotnica x ja, I=0,1,..,N-1 wewnątrz segmentu [ A;B]:
 , (1.27)
, (1.27)
Gdzie ja I AI dla różnych N podane są w podręcznikach. Na przykład kiedy N=2 ![]() A 0 =A 1=1; Na N=3: T 0 = t 2" 0,775, T 1 =0, A 0 =A 2" 0,555, A 1" 0,889.
A 0 =A 1=1; Na N=3: T 0 = t 2" 0,775, T 1 =0, A 0 =A 2" 0,555, A 1" 0,889.
Wzór kwadraturowy Gaussa
 otrzymane przy funkcji wagi równej jedności p(x)= 1 i węzły x ja, które są pierwiastkami wielomianów Legendre'a
otrzymane przy funkcji wagi równej jedności p(x)= 1 i węzły x ja, które są pierwiastkami wielomianów Legendre'a
![]()
Szanse AIłatwo obliczyć za pomocą wzorów
![]() I=0,1,2,...N.
I=0,1,2,...N.
Wartości węzłów i współczynników dla n=2,3,4,5 podano w tabeli
| Zamówienie | Węzły | Szanse |
| N=2 | x 1=0 x 0 =-x2=0.7745966692 | 1=8/9 ZA 0 = ZA 2=5/9 |
| N=3 | x 2 =-x 1=0.3399810436 x 3 =-x0=0.8611363116 | ZA 1 = ZA 2=0.6521451549 ZA 0 = ZA 3=0.6521451549 |
| n=4 | X 2 = 0 X 3 = -X 1 = 0.5384693101 X 4 =-X 0 =0.9061798459 | A 0 =0.568888899 A 3 =A 1 =0.4786286705 A 0 =A 4 =0.2869268851 |
| N=5 | X 5 = -X 0 =0.9324695142 X 4 = -X 1 =0.6612093865 X 3 = -X 2 =0.2386191861 | A 5 =A 0 =0.1713244924 A 4 =A 1 =0.3607615730 A 3 =A 2 =0.4679139346 |
Przykład. Oblicz wartość, korzystając ze wzoru Gaussa dla N=2:
Dokładna wartość: ![]() .
.
Algorytm obliczania całki według wzoru Gaussa przewiduje nie podwojenie liczby mikrosegmentów, ale zwiększenie liczby rzędnych o 1 i porównanie uzyskanych wartości całki. Zaletą wzoru Gaussa jest duża dokładność przy stosunkowo małej liczbie rzędnych. Wady: niewygodne w przypadku obliczeń ręcznych; muszą być przechowywane w pamięci komputera ja, AI dla różnych N.
Błąd wzoru na kwadraturę Gaussa na odcinku będzie w tym samym czasie. Dla wzoru na resztę członu będzie tam, gdzie współczynnik α N szybko maleje wraz ze wzrostem N. Tutaj ![]()
Wzory Gaussa zapewniają wysoką dokładność już przy niewielkiej liczbie węzłów (od 4 do 10), w tym przypadku w praktycznych obliczeniach liczba węzłów waha się od kilkuset do kilku tysięcy. Zauważamy również, że wagi kwadratur Gaussa są zawsze dodatnie, co zapewnia stabilność algorytmu obliczania sum