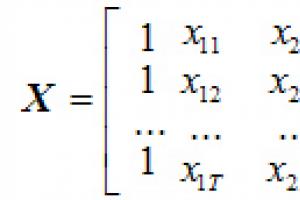Lineaarne regressioon. Vähimruutude meetodi (LSM) kasutamine. Katseandmete lähendamine. Vähimruutude meetod Vähimruutude meetod 3 muutuja korral
Mis leiab kõige laiemat rakendust erinevates teadus- ja praktikavaldkondades. See võib olla füüsika, keemia, bioloogia, majandus, sotsioloogia, psühholoogia ja nii edasi ja nii edasi. Saatuse tahtel pean sageli tegelema majandusega ja seetõttu korraldan täna teile pileti imelisse riiki nimega Ökonomeetria=) … Kuidas sa seda ei taha?! Seal on väga hea – sa pead lihtsalt otsustama! …Aga mida sa ilmselt kindlasti tahad, on õppida probleeme lahendama vähimruudud. Ja eriti usinad lugejad õpivad neid lahendama mitte ainult täpselt, vaid ka VÄGA KIIRESTI ;-) Aga enne probleemi üldine avaldus+ seotud näide:
Laske uurida näitajaid mõnes ainevaldkonnas, millel on kvantitatiivne väljendus. Samas on põhjust arvata, et näitaja sõltub indikaatorist. See oletus võib olla nii teaduslik hüpotees kui ka põhineda elementaarsel tervel mõistusel. Jätame teaduse aga kõrvale ja uurime isuäratavamaid valdkondi – nimelt toidupoode. Tähistage:
– toidupoe kaubanduspind, ruutmeetrit,
- toidupoe aastakäive, miljonit rubla.
On täiesti selge, et mida suurem on kaupluse pindala, seda suurem on enamikul juhtudel selle käive.
Oletame, et pärast vaatluste / katsete / arvutuste / tamburiiniga tantsimist on meie käsutuses numbrilised andmed: 
Toidupoodidega on minu arvates kõik selge: - see on 1. poe pindala, - selle aastakäive, - 2. kaupluse pind, - selle aastakäive jne. Muide, salastatud materjalidele ligipääs pole üldse vajalik – üsna täpse hinnangu käibele saab kasutades matemaatiline statistika. Kuid ärge laske end segada, kommertsspionaaži kursus on juba tasutud =)
Tabeliandmeid saab kirjutada ka punktide kujul ja kujutada meile tavapärasel viisil. Descartes'i süsteem .
Vastame olulisele küsimusele: mitu punkti on vaja kvalitatiivse uuringu jaoks?
Mida suurem, seda parem. Minimaalne lubatud komplekt koosneb 5-6 punktist. Lisaks ei tohiks väikese andmehulga korral valimisse kaasata "ebanormaalseid" tulemusi. Nii võib näiteks väike eliitpood aidata suurusjärgus rohkem kui “oma kolleegid”, moonutades seeläbi üldist mustrit, mis tuleb leida!
Kui see on üsna lihtne, peame valima funktsiooni, ajakava mis läbib punktidele võimalikult lähedalt ![]() . Sellist funktsiooni nimetatakse ligikaudne
(ligikaudne – ligikaudne) või teoreetiline funktsioon
. Üldiselt ilmub siin kohe ilmne "teeskleja" - kõrge astme polünoom, mille graafik läbib KÕIKI punkte. Kuid see valik on keeruline ja sageli lihtsalt vale. (kuna diagramm "tuuleb" kogu aeg ja kajastab halvasti peamist trendi).
. Sellist funktsiooni nimetatakse ligikaudne
(ligikaudne – ligikaudne) või teoreetiline funktsioon
. Üldiselt ilmub siin kohe ilmne "teeskleja" - kõrge astme polünoom, mille graafik läbib KÕIKI punkte. Kuid see valik on keeruline ja sageli lihtsalt vale. (kuna diagramm "tuuleb" kogu aeg ja kajastab halvasti peamist trendi).
Seega peab soovitud funktsioon olema piisavalt lihtne ja samas peegeldama adekvaatselt sõltuvust. Nagu võite arvata, nimetatakse ühte selliste funktsioonide leidmise meetoditest vähimruudud. Esiteks analüüsime selle olemust üldiselt. Olgu mõni funktsioon katseandmetele ligikaudne: 
Kuidas hinnata selle lähenduse täpsust? Arvutagem välja ka eksperimentaalsete ja funktsionaalsete väärtuste erinevused (hälbed). (uurime joonist). Esimene mõte, mis pähe tuleb, on hinnata, kui suur summa on, kuid probleem on selles, et erinevused võivad olla negatiivsed. (Näiteks, ![]() )
ja sellisest summeerimisest tulenevad kõrvalekalded tühistavad üksteist. Seetõttu soovitab see lähenemise täpsuse hinnanguna võtta summa moodulid kõrvalekalded:
)
ja sellisest summeerimisest tulenevad kõrvalekalded tühistavad üksteist. Seetõttu soovitab see lähenemise täpsuse hinnanguna võtta summa moodulid kõrvalekalded:
![]() või volditud kujul: (äkki, kes ei tea: on summa ikoon ja abimuutuja - "loendur", mis võtab väärtused vahemikus 1 kuni ).
või volditud kujul: (äkki, kes ei tea: on summa ikoon ja abimuutuja - "loendur", mis võtab väärtused vahemikus 1 kuni ).
Lähendades katsepunkte erinevate funktsioonidega, saame erinevad väärtused ja on ilmne, et kus see summa on väiksem, on see funktsioon täpsem.
Selline meetod on olemas ja seda nimetatakse vähima mooduli meetod. Praktikas on see aga palju laiemalt levinud. vähima ruudu meetod, kus võimalikud negatiivsed väärtused ei välistata mitte mooduli, vaid hälvete ruudustamisel:
![]() , misjärel suunatakse jõupingutused sellise funktsiooni valikule, et hälvete ruudu summa
, misjärel suunatakse jõupingutused sellise funktsiooni valikule, et hälvete ruudu summa ![]() oli võimalikult väike. Tegelikult sellest ka meetodi nimi.
oli võimalikult väike. Tegelikult sellest ka meetodi nimi.
Ja nüüd pöördume tagasi teise olulise punkti juurde: nagu eespool märgitud, peaks valitud funktsioon olema üsna lihtne - kuid selliseid funktsioone on ka palju: lineaarne , hüperboolne, eksponentsiaalne, logaritmiline, ruutkeskne jne. Ja loomulikult tahaks siinkohal kohe "tegevusvaldkonda vähendada". Millist funktsioonide klassi uuringuks valida? Primitiivne, kuid tõhus tehnika:
- Lihtsaim viis punktide tõmbamiseks ![]() joonisel ja analüüsida nende asukohta. Kui need kipuvad olema sirgjoonelised, siis peaksite otsima sirgjoone võrrand
joonisel ja analüüsida nende asukohta. Kui need kipuvad olema sirgjoonelised, siis peaksite otsima sirgjoone võrrand ![]() optimaalsete väärtustega ja . Ehk siis ülesandeks on leida SELLISED koefitsiendid – et hälvete ruudu summa oleks kõige väiksem.
optimaalsete väärtustega ja . Ehk siis ülesandeks on leida SELLISED koefitsiendid – et hälvete ruudu summa oleks kõige väiksem.
Kui punktid asuvad näiteks mööda hüperbool, siis on selge, et lineaarfunktsioon annab halva lähenduse. Sel juhul otsime hüperboolvõrrandi jaoks kõige soodsamaid koefitsiente ![]() - need, mis annavad minimaalse ruutude summa
- need, mis annavad minimaalse ruutude summa  .
.
Nüüd pange tähele, et mõlemal juhul räägime kahe muutuja funktsioonid, kelle argumendid on otsis sõltuvuse valikuid:
Ja sisuliselt peame lahendama standardprobleemi – leidma vähemalt kahe muutuja funktsioon.
Tuletage meelde meie näidet: oletagem, et "poe" punktid kipuvad asuma sirgjooneliselt ja on põhjust uskuda nende olemasolu lineaarne sõltuvus käive kauplemispiirkonnast. Leiame SELLISED koefitsiendid "a" ja "olla", et hälvete ruudu summa ![]() oli väikseim. Kõik nagu tavaliselt – kõigepealt I järgu osatuletised. Vastavalt lineaarsuse reegel saate vahet teha otse summaikooni all:
oli väikseim. Kõik nagu tavaliselt – kõigepealt I järgu osatuletised. Vastavalt lineaarsuse reegel saate vahet teha otse summaikooni all: 
Kui soovite seda teavet kasutada essee või kursusetöö jaoks, olen allikate loendis oleva lingi eest väga tänulik, nii üksikasjalikke arvutusi ei leia kuskil: 
Teeme standardse süsteemi: 
Vähendame iga võrrandit "kahega" ja lisaks "lõhkume" summad: 
Märge
: analüüsige iseseisvalt, miks "a" ja "be" saab summaikoonist välja võtta. Muide, formaalselt saab seda teha summaga![]()
Kirjutame süsteemi ümber "rakendatud" kujul: 
mille järel hakatakse koostama meie probleemi lahendamise algoritmi:
Kas me teame punktide koordinaate? Me teame. Summad ![]() kas leiame? Kergesti. Koostame kõige lihtsama kahe tundmatuga lineaarvõrrandi süsteem("a" ja "beh"). Lahendame süsteemi nt Crameri meetod, mille tulemuseks on statsionaarne punkt . Kontrollimine ekstreemumi jaoks piisav tingimus, saame kontrollida, et siinkohal on funktsioon
kas leiame? Kergesti. Koostame kõige lihtsama kahe tundmatuga lineaarvõrrandi süsteem("a" ja "beh"). Lahendame süsteemi nt Crameri meetod, mille tulemuseks on statsionaarne punkt . Kontrollimine ekstreemumi jaoks piisav tingimus, saame kontrollida, et siinkohal on funktsioon ![]() ulatub täpselt miinimum. Kontrollimine on seotud täiendavate arvutustega ja seetõttu jätame selle kulisside taha. (vajadusel saab puuduvat kaadrit vaadata). Teeme lõpliku järelduse:
ulatub täpselt miinimum. Kontrollimine on seotud täiendavate arvutustega ja seetõttu jätame selle kulisside taha. (vajadusel saab puuduvat kaadrit vaadata). Teeme lõpliku järelduse:
Funktsioon ![]() parim viis (vähemalt võrreldes kõigi teiste lineaarsete funktsioonidega) toob katsepunktid lähemale
parim viis (vähemalt võrreldes kõigi teiste lineaarsete funktsioonidega) toob katsepunktid lähemale ![]() . Jämedalt öeldes läbib selle graafik nendele punktidele võimalikult lähedalt. Traditsiooni järgi ökonomeetria nimetatakse ka saadud lähendusfunktsiooni paaris lineaarse regressiooni võrrand
.
. Jämedalt öeldes läbib selle graafik nendele punktidele võimalikult lähedalt. Traditsiooni järgi ökonomeetria nimetatakse ka saadud lähendusfunktsiooni paaris lineaarse regressiooni võrrand
.
Vaadeldav probleem on väga praktilise tähtsusega. Meie näite olukorras võrrand ![]() võimaldab ennustada, millist käivet ("yig") on poes ühe või teise müügipinna väärtusega ("x" üks või teine tähendus). Jah, saadud prognoos on vaid prognoos, kuid paljudel juhtudel osutub see üsna täpseks.
võimaldab ennustada, millist käivet ("yig") on poes ühe või teise müügipinna väärtusega ("x" üks või teine tähendus). Jah, saadud prognoos on vaid prognoos, kuid paljudel juhtudel osutub see üsna täpseks.
Analüüsin ainult ühte probleemi "päris" numbritega, kuna selles pole raskusi - kõik arvutused on 7.-8. klassis kooli õppekava tasemel. 95 protsendil juhtudest palutakse teil leida lihtsalt lineaarne funktsioon, kuid artikli lõpus näitan, et optimaalse hüperbooli, astendaja ja mõne muu funktsiooni võrrandite leidmine pole enam keeruline.
Tegelikult jääb üle lubatud maiuspalade levitamine - nii et õpiksite selliseid näiteid mitte ainult täpselt, vaid ka kiiresti lahendama. Uurime hoolikalt standardit:
Ülesanne
Kahe näitaja vahelise seose uurimise tulemusena saadi järgmised numbripaarid: 
Vähimruutude meetodil leidke lineaarfunktsioon, mis kõige paremini lähendab empiirilist väärtust (kogenud) andmeid. Tehke joonis, millele joonistage Descartes'i ristkülikukujulises koordinaatsüsteemis katsepunktid ja lähendusfunktsiooni graafik ![]() . Leidke empiiriliste ja teoreetiliste väärtuste vaheliste hälvete ruudu summa. Uurige, kas funktsioon on parem (vähimruutude meetodil) ligikaudsed katsepunktid.
. Leidke empiiriliste ja teoreetiliste väärtuste vaheliste hälvete ruudu summa. Uurige, kas funktsioon on parem (vähimruutude meetodil) ligikaudsed katsepunktid.
Pange tähele, et "x" väärtused on loomulikud väärtused ja sellel on iseloomulik tähenduslik tähendus, millest räägin veidi hiljem; kuid need võivad muidugi olla murdosa. Lisaks võivad nii "X" kui ka "G" väärtused olenevalt konkreetse ülesande sisust olla täielikult või osaliselt negatiivsed. Noh, meile on antud "näotu" ülesanne ja me alustame sellega lahendus:
Süsteemi lahendusena leiame optimaalse funktsiooni koefitsiendid: 
Kompaktsema tähistuse huvides võib muutuja “loendur” ära jätta, kuna on juba selge, et summeerimine toimub vahemikus 1 kuni .
Vajalikud summad on mugavam arvutada tabeli kujul: 
Arvutamist saab teha mikrokalkulaatoriga, kuid palju parem on kasutada Excelit - nii kiiremini kui ka vigadeta; vaata lühikest videot:
Seega saame järgmise süsteem:![]()
Siin saate korrutada teise võrrandi 3-ga ja lahutage 1. võrrandist liige liikme haaval 2.. Kuid see on õnn - praktikas pole süsteemid sageli andekad ja sellistel juhtudel säästab see Crameri meetod:
, seega on süsteemil ainulaadne lahendus.

Teeme kontrolli. Ma saan aru, et ma ei taha, aga miks jätta vahele vigu, kus neist ei saa mööda minna? Asendage leitud lahendus iga süsteemi võrrandi vasakpoolsesse serva:
Vastavate võrrandite õiged osad saadakse, mis tähendab, et süsteem on õigesti lahendatud.
Seega soovitud ligikaudne funktsioon: – alates kõik lineaarsed funktsioonid katseandmed on selle järgi kõige paremini ligikaudsed.
Erinevalt sirge
kaupluse käibe sõltuvus oma pindalast, leitud sõltuvus on tagurpidi
(põhimõte "mida rohkem - seda vähem"), ja selle fakti paljastab kohe negatiivne nurga koefitsient. Funktsioon ![]() teatab meile, et teatud näitaja suurenemisel 1 ühiku võrra sõltuva näitaja väärtus väheneb keskmine 0,65 ühiku võrra. Nagu öeldakse, mida kõrgem on tatra hind, seda vähem müüakse.
teatab meile, et teatud näitaja suurenemisel 1 ühiku võrra sõltuva näitaja väärtus väheneb keskmine 0,65 ühiku võrra. Nagu öeldakse, mida kõrgem on tatra hind, seda vähem müüakse.
Ligikaudse funktsiooni joonistamiseks leiame kaks selle väärtust:
ja teostage joonis: 
Ehitatud rida nimetatakse trendijoon
(nimelt lineaarne trendijoon, st üldiselt ei pruugi trend olla sirgjoon). Kõik on tuttavad väljendiga "trendis olema" ja ma arvan, et see termin ei vaja täiendavaid kommentaare.
Arvutage kõrvalekallete ruudu summa ![]() empiiriliste ja teoreetiliste väärtuste vahel. Geomeetriliselt on see "karmiinpunaste" segmentide pikkuste ruutude summa (neist kaks on nii väikesed, et ei näe neid isegi).
empiiriliste ja teoreetiliste väärtuste vahel. Geomeetriliselt on see "karmiinpunaste" segmentide pikkuste ruutude summa (neist kaks on nii väikesed, et ei näe neid isegi).
Võtame arvutused kokku tabelis: 
Neid saab jälle käsitsi läbi viia, igaks juhuks toon näite 1. punkti kohta: ![]()
kuid palju tõhusam on teha juba tuntud viis:
Kordame: mis on tulemuse tähendus? Alates kõik lineaarsed funktsioonid funktsiooni ![]() eksponent on väikseim, see tähendab, et see on oma perekonna parim lähendus. Ja siin, muide, pole probleemi viimane küsimus juhuslik: mis siis, kui pakutud eksponentsiaalne funktsioon
eksponent on väikseim, see tähendab, et see on oma perekonna parim lähendus. Ja siin, muide, pole probleemi viimane küsimus juhuslik: mis siis, kui pakutud eksponentsiaalne funktsioon ![]() kas katsepunkte on parem lähendada?
kas katsepunkte on parem lähendada?
Leiame vastava hälbete ruudusumma - nende eristamiseks tähistan need tähega "epsilon". Tehnika on täpselt sama: 
Ja veelkord iga 1. punkti tulearvutuse kohta: 
Excelis kasutame standardfunktsiooni EXP (Süntaksi leiate Exceli spikrist).
Järeldus: , seega lähendab eksponentsiaalfunktsioon katsepunkte halvemini kui sirgjoon ![]() .
.
Kuid siin tuleb märkida, et "hullem" on ei tähenda veel, Mis on valesti. Nüüd koostasin selle eksponentsiaalfunktsiooni graafiku – ja see läbib ka punktide lähedalt ![]() - nii palju, et ilma analüütilise uuringuta on raske öelda, milline funktsioon on täpsem.
- nii palju, et ilma analüütilise uuringuta on raske öelda, milline funktsioon on täpsem.
See lõpetab lahenduse ja ma pöördun tagasi argumendi loodusväärtuste küsimuse juurde. Erinevates uuringutes on reeglina majanduslikud või sotsioloogilised kuud, aastad või muud võrdsed ajavahemikud nummerdatud loomuliku "X-iga". Mõelge näiteks sellisele probleemile.
Näide.
Eksperimentaalsed andmed muutujate väärtuste kohta X Ja juures on toodud tabelis.
Nende joondamise tulemusena funktsioon ![]()
Kasutades vähima ruudu meetod, lähendage neid andmeid lineaarse sõltuvusega y=kirves+b(leidke valikud A Ja b). Uurige, milline kahest joonest on parem (vähimruutude meetodi mõttes), mis joondab katseandmeid. Tee joonistus.
Vähimruutude meetodi (LSM) olemus.
Ülesanne on leida lineaarsed sõltuvuskoefitsiendid, mille puhul on kahe muutuja funktsioon A Ja b
![]() võtab väikseima väärtuse. St andmeid arvestades A Ja b katseandmete ruutude hälvete summa leitud sirgest on väikseim. See on kogu vähimruutude meetodi mõte.
võtab väikseima väärtuse. St andmeid arvestades A Ja b katseandmete ruutude hälvete summa leitud sirgest on väikseim. See on kogu vähimruutude meetodi mõte.
Seega taandatakse näite lahendus kahe muutuja funktsiooni ekstreemumi leidmisele.
Valemite tuletamine koefitsientide leidmiseks.
Koostatakse ja lahendatakse kahest võrrandist koosnev süsteem kahe tundmatuga. Funktsioonide osatuletiste leidmine ![]() muutujate järgi A Ja b, võrdsustame need tuletised nulliga.
muutujate järgi A Ja b, võrdsustame need tuletised nulliga. 
Lahendame saadud võrrandisüsteemi mis tahes meetodiga (näiteks asendusmeetod või Crameri meetod) ja saada valemid koefitsientide leidmiseks vähimruutude meetodi (LSM) abil. 
Andmetega A Ja b funktsiooni ![]() võtab väikseima väärtuse. Selle fakti tõestus on esitatud lehe lõpus oleva teksti all.
võtab väikseima väärtuse. Selle fakti tõestus on esitatud lehe lõpus oleva teksti all.
See on kogu vähimruutude meetod. Valem parameetri leidmiseks a sisaldab summasid ,, ja parameetrit n- katseandmete hulk. Nende summade väärtused on soovitatav arvutada eraldi. Koefitsient b leitud pärast arvutamist a.
On aeg meenutada algset näidet.
Lahendus.
Meie näites n = 5. Nõutavate koefitsientide valemites sisalduvate summade arvutamise mugavuse huvides täidame tabeli. 
Tabeli neljanda rea väärtused saadakse, korrutades iga numbri 2. rea väärtused 3. rea väärtustega i.
Tabeli viienda rea väärtused saadakse iga numbri 2. rea väärtuste ruudustamisel i.
Tabeli viimase veeru väärtused on ridade väärtuste summad.
Koefitsientide leidmiseks kasutame vähimruutude meetodi valemeid A Ja b. Asendame neis vastavad väärtused tabeli viimasest veerust: 
Seega y=0,165x+2,184 on soovitud ligikaudne sirgjoon.
Jääb välja selgitada, milline ridadest y=0,165x+2,184 või ![]() lähendab paremini algandmeid, st teha hinnang vähimruutude meetodil.
lähendab paremini algandmeid, st teha hinnang vähimruutude meetodil.
Vähimruutude meetodi vea hindamine.
Selleks peate arvutama nendelt ridadelt algandmete ruuduhälbete summad ![]() Ja
Ja ![]() , vastab väiksem väärtus joonele, mis lähendab paremini algandmeid vähimruutude meetodil.
, vastab väiksem väärtus joonele, mis lähendab paremini algandmeid vähimruutude meetodil. 
Alates , siis rida y=0,165x+2,184 läheneb paremini algandmetele.
Vähimruutude meetodi (LSM) graafiline illustratsioon.
Tabelites näeb kõik suurepärane välja. Punane joon on leitud joon y=0,165x+2,184, sinine joon on ![]() , on roosad täpid algandmed.
, on roosad täpid algandmed.

Praktikas kasutatakse mitmesuguste protsesside - eriti majanduslike, füüsiliste, tehniliste, sotsiaalsete - modelleerimisel laialdaselt üht või teist meetodit funktsioonide ligikaudsete väärtuste arvutamiseks nende teadaolevatest väärtustest teatud kindlates punktides.
Seda tüüpi funktsioonide lähendamisel tekivad sageli probleemid:
ligikaudsete valemite koostamisel uuritava protsessi iseloomulike suuruste väärtuste arvutamiseks vastavalt katse tulemusel saadud tabeliandmetele;
arvulises integreerimises, diferentseerimises, diferentsiaalvõrrandite lahendamises jne;
kui on vaja arvutada funktsioonide väärtused vaadeldava intervalli vahepunktides;
protsessi iseloomulike suuruste väärtuste määramisel väljaspool vaadeldavat intervalli, eriti prognoosimisel.
Kui teatud tabeliga määratud protsessi modelleerimiseks konstrueeritakse funktsioon, mis seda protsessi ligikaudselt kirjeldab vähimruutude meetodil, nimetatakse seda lähendavaks funktsiooniks (regressioon) ja lähendavate funktsioonide konstrueerimise ülesanne ise olla ligikaudne probleem.
Käesolevas artiklis käsitletakse MS Exceli paketi võimalusi selliste ülesannete lahendamiseks, lisaks on toodud meetodid ja tehnikad regressioonide konstrueerimiseks (loomiseks) tabeliliselt etteantud funktsioonidele (mis on regressioonanalüüsi aluseks).
Excelis on regressioonide koostamiseks kaks võimalust.
Valitud regressioonide (trendijoonte) lisamine uuritava protsessi tunnuse andmetabeli alusel koostatud diagrammile (saadaval ainult diagrammi koostamisel);
Exceli töölehe sisseehitatud statistiliste funktsioonide kasutamine, mis võimaldab saada regressioone (trendijooni) otse lähteandmete tabelist.
Trendijoonte lisamine diagrammile
Teatud protsessi kirjeldava ja diagrammiga kujutatud andmetabeli jaoks on Excelil tõhus regressioonianalüüsi tööriist, mis võimaldab teil:
ehitada vähimruutude meetodi alusel ja lisada diagrammile viis tüüpi regressiooni, mis modelleerivad uuritavat protsessi erineva täpsusastmega;
lisada diagrammile konstrueeritud regressiooni võrrand;
määrata valitud regressiooni vastavuse aste diagrammil kuvatavatele andmetele.
Diagrammi andmete põhjal võimaldab Excel saada lineaarseid, polünoomilisi, logaritmilisi, eksponentsiaalseid ja eksponentsiaalseid regressioonitüüpe, mis on antud võrrandiga:
y = y(x)
kus x on sõltumatu muutuja, mis võtab sageli naturaalarvude jada (1; 2; 3; ...) väärtused ja loob näiteks uuritava protsessi aja loenduse (karakteristikud) .
1 . Lineaarne regressioon on hea konstantse kiirusega suurenevate või vähenevate tunnuste modelleerimiseks. See on uuritava protsessi lihtsaim mudel. See on ehitatud vastavalt võrrandile:
y=mx+b
kus m on lineaarse regressiooni kalde puutuja x-telje suhtes; b - lineaarse regressiooni ja y-telje lõikepunkti koordinaat.
2 . Polünoomiline trendijoon on kasulik selliste omaduste kirjeldamiseks, millel on mitu erinevat äärmust (kõrgemad ja madalad). Polünoomi astme valiku määrab uuritava tunnuse äärmuste arv. Seega võib teise astme polünoom hästi kirjeldada protsessi, millel on ainult üks maksimum või miinimum; kolmanda astme polünoom - mitte rohkem kui kaks äärmust; neljanda astme polünoom - mitte rohkem kui kolm ekstreemi jne.
Sel juhul koostatakse trendijoon vastavalt võrrandile:
y = c0 + c1x + c2x2 + c3x3 + c4x4 + c5x5 + c6x6
kus koefitsiendid c0, c1, c2,...c6 on konstandid, mille väärtused määratakse ehituse käigus.
3 . Logaritmilist trendijoont kasutatakse edukalt karakteristikute modelleerimisel, mille väärtused muutuvad alguses kiiresti ja seejärel järk-järgult stabiliseeruvad.
y = c ln(x) + b
4 . Jõutrendi joon annab häid tulemusi, kui uuritud sõltuvuse väärtusi iseloomustab pidev kasvukiiruse muutus. Sellise sõltuvuse näide võib olla auto ühtlaselt kiirendatud liikumise graafik. Kui andmetes on null või negatiivsed väärtused, ei saa te võimsuse trendijoont kasutada.
See on ehitatud vastavalt võrrandile:
y = cxb
kus koefitsiendid b, c on konstandid.
5 . Kui andmete muutumise kiirus pidevalt kasvab, tuleks kasutada eksponentsiaalset trendijoont. Null- või negatiivseid väärtusi sisaldavate andmete puhul ei saa seda tüüpi lähendust samuti kasutada.
See on ehitatud vastavalt võrrandile:
y=cebx
kus koefitsiendid b, c on konstandid.
Trendijoone valimisel arvutab Excel automaatselt välja R2 väärtuse, mis iseloomustab lähenduse täpsust: mida lähemal on R2 väärtus ühele, seda usaldusväärsemalt läheneb trendijoon uuritavale protsessile. Vajadusel saab diagrammil alati kuvada R2 väärtuse.
Määratakse valemiga:

Andmeseeriale trendijoone lisamiseks tehke järgmist.
aktiveerige andmeseeria põhjal koostatud diagramm, st klõpsake diagrammialal. Diagramm kuvatakse peamenüüs;
peale sellel üksusel klõpsamist ilmub ekraanile menüü, kus tuleb valida käsk Lisa trendijoon.
Samad toimingud on hõlpsasti rakendatavad, kui hõljutate kursorit ühele andmeseeriale vastava graafiku kohal ja paremklõpsate; valige kuvatavas kontekstimenüüs käsk Lisa trendijoon. Ekraanile ilmub dialoogiboks Trendline, kus on avatud vahekaart Tüüp (joonis 1).

Pärast seda vajate:
Valige vahekaardil Tüüp soovitud trendijoone tüüp (vaikimisi on valitud Lineaarne). Polünoomi tüübi jaoks määrake väljal Degree valitud polünoomi aste.
1 . Väljal Built on Series on loetletud kõik kõnealuse diagrammi andmesarjad. Trendijoone lisamiseks kindlale andmeseeriale valige väljal Built on seeria selle nimi.

Vajadusel saate vahekaardile Parameetrid minnes (joonis 2) määrata trendijoonele järgmised parameetrid:
muutke väljal Lähendava (silutud) kõvera nimi trendijoone nime.
määrata väljale Prognoos prognoosi perioodide arv (edasi või tagasi);
kuva diagrammialal trendijoone võrrandit, mille puhul tuleks lubada ruut näita võrrandit diagrammil;
kuva diagrammi alas lähenduse usaldusväärsuse väärtus R2, mille jaoks tuleks lubada märkeruut pane diagrammile lähenduse usaldusväärsus (R^2);
määrake trendijoone lõikepunkt Y-teljega, mille jaoks peaksite märkima kõvera ristumiskoha Y-teljega punktis;
dialoogiboksi sulgemiseks klõpsake nuppu OK.
Juba ehitatud trendijoone redigeerimise alustamiseks on kolm võimalust:
pärast trendijoone valimist kasuta menüüst Vorming käsku Selected trend line;
vali kontekstimenüüst käsk Format Trendline, mille kutsumiseks tehakse trendijoonel paremklõps;
topeltklõpsuga trendijoonel.
Ekraanile ilmub Trendijoone vormindamise dialoogiboks (joonis 3), mis sisaldab kolme vahekaarti: Vaade, Tüüp, Parameetrid ja kahe viimase sisu kattub täielikult Trendline dialoogiboksi sarnaste vahekaartidega (joonis 1-2). ). Vahekaardil Vaade saate määrata joone tüübi, värvi ja paksuse.

Juba koostatud trendijoone kustutamiseks valige kustutatav trendijoon ja vajutage klahvi Kustuta.
Vaadeldava regressioonanalüüsi tööriista eelised on järgmised:
trendijoone joonistamise suhteline lihtsus graafikutele ilma selle jaoks andmetabelit loomata;
üsna lai nimekiri pakutud trendijoonte tüüpidest ja see loend sisaldab kõige sagedamini kasutatavaid regressioonitüüpe;
võimalus ennustada uuritava protsessi käitumist suvalise (terve mõistuse piires) arvu sammude võrra nii edasi kui ka tagasi;
trendijoone võrrandi saamise võimalus analüütilisel kujul;
vajaduse korral võimalus saada hinnang lähenduse usaldusväärsuse kohta.
Puudused hõlmavad järgmisi punkte:
trendijoone konstrueerimine toimub ainult siis, kui on olemas andmeseeriale üles ehitatud diagramm;
uuritava karakteristiku andmeseeriate genereerimise protsess selle jaoks saadud trendijoone võrrandite põhjal on mõnevõrra segane: soovitud regressioonivõrrandeid värskendatakse iga algse andmerea väärtuste muutusega, kuid ainult diagrammi ala piires. , samas kui vana joonvõrrandi trendi alusel moodustatud andmeread jääb muutumatuks;
PivotChart-liigenddiagrammi aruannetes diagrammivaate või sellega seotud PivotTable-liigendtabeli aruande muutmisel olemasolevaid trendijooni ei säilitata, mis tähendab, et enne trendijoonte joonistamist või muul viisil PivotChart-liigenddiagrammi aruande vormindamist peate veenduma, et aruande paigutus vastab teie nõuetele.
Trendijooni saab lisada andmeseeriatele, mis on esitatud diagrammidel, nagu graafik, histogramm, lamedad normaliseerimata aladiagrammid, tulp-, hajuvus-, mull- ja aktsiadiagrammid.
Trendijooni ei saa lisada andmeseeriatele 3D-, Standard-, radari-, sektor- ja sõõrikudiagrammidel.
Sisseehitatud Exceli funktsioonide kasutamine
Excel pakub ka regressioonianalüüsi tööriista trendijoonte joonistamiseks väljaspool diagrammiala. Sel eesmärgil saab kasutada mitmeid statistilise töölehe funktsioone, kuid kõik need võimaldavad koostada ainult lineaarseid või eksponentsiaalseid regressioone.
Excelil on lineaarse regressiooni loomiseks mitu funktsiooni, eelkõige:
KALVAD ja LÕIKAD.
TREND;
Lisaks mitmed funktsioonid eksponentsiaalse trendijoone koostamiseks, eriti:
LGRFPumbes.
Tuleb märkida, et TREND ja GROWTH funktsioonide abil regressioonide koostamise tehnikad on praktiliselt samad. Sama võib öelda ka funktsioonipaari LINEST ja LGRFPRIBL kohta. Nende nelja funktsiooni puhul kasutatakse väärtuste tabeli loomisel Exceli funktsioone, näiteks massiivi valemeid, mis segavad regressioonide koostamise protsessi mõnevõrra. Samuti märgime, et lineaarse regressiooni konstrueerimist on meie arvates kõige lihtsam teostada funktsioonide SLOPE ja INTERCEPT abil, kus esimene neist määrab lineaarse regressiooni kalde ja teine regressiooniga ära lõigatud lõigu. y-teljel.
Regressioonanalüüsi sisseehitatud funktsioonide tööriista eelised on järgmised:
üsna lihtne protsess uuritava tunnuse sama tüüpi andmeseeriate moodustamiseks kõigi trendijooni määravate sisseehitatud statistiliste funktsioonide jaoks;
standardtehnika genereeritud andmeseeriate põhjal trendijoonte koostamiseks;
võime ennustada uuritava protsessi käitumist vajaliku arvu samme edasi või tagasi.
Ja miinuste hulka kuulub asjaolu, et Excelil pole sisseehitatud funktsioone muud tüüpi (välja arvatud lineaarsed ja eksponentsiaalsed) trendijoonte loomiseks. See asjaolu ei võimalda sageli valida uuritava protsessi kohta piisavalt täpset mudelit, samuti saada reaalsusele lähedasi prognoose. Lisaks ei ole funktsioonide TREND ja GROW kasutamisel teada trendijoonte võrrandid.
Tuleb märkida, et autorid ei seadnud artikli eesmärgiks esitada regressioonanalüüsi käiku erineva täielikkuse astmega. Selle põhiülesanne on konkreetsete näidete abil näidata Exceli paketi võimalusi lähendusülesannete lahendamisel; demonstreerida, millised tõhusad tööriistad on Excelil regressioonide koostamiseks ja prognoosimiseks; illustreerida, kui suhteliselt lihtsalt saab selliseid probleeme lahendada isegi kasutaja, kes ei tunne sügavaid regressioonanalüüsi teadmisi.
Näited konkreetsete probleemide lahendamisest
Mõelge konkreetsete probleemide lahendamisele Exceli paketi loetletud tööriistade abil.
Ülesanne 1
Tabeliga autotranspordiettevõtte kasumi kohta aastatel 1995-2002. peate tegema järgmist.
Koostage diagramm.
Lisage diagrammile lineaarsed ja polünoomilised (ruut- ja kuup-) trendijooned.
Trendijoone võrrandite abil hankige tabeliandmed ettevõtte kasumi kohta iga trendijoone kohta aastatel 1995–2004.
Tehke ettevõtte kasumiprognoos aastateks 2003 ja 2004.
Probleemi lahendus

Exceli töölehe lahtrite vahemikku A4:C11 sisestame joonisel fig. 4.
Olles valinud lahtrite vahemiku B4:C11, koostame diagrammi.
Aktiveerime konstrueeritud diagrammi ja ülalkirjeldatud meetodil peale trendijoone tüübi valimist Trend Line dialoogiaknas (vt joon. 1) lisame diagrammile vaheldumisi lineaarsed, ruut- ja kuuptrendijooned. Samas dialoogiboksis avage vahekaart Parameetrid (vt joonis 2), väljale Name of the lähendava (silutud) kõvera nimi sisestage lisatava trendi nimi ja määrake väljale Forecast forward for: periods. väärtus 2, kuna plaanitakse teha kasumiprognoos kaheks aastaks ette. Regressioonivõrrandi ja lähenduse usaldusväärsuse R2 väärtuse kuvamiseks diagrammialal lubage märkeruudud Kuva võrrand ekraanil ja asetage diagrammile lähenduse usaldusväärsuse väärtus (R^2). Parema visuaalse tajumise huvides muudame joonistatud trendijoonte tüüpi, värvi ja paksust, mille jaoks kasutame dialoogiboksi Trend Line Format vahekaarti Vaade (vt joonis 3). Saadud diagramm koos lisatud trendijoontega on näidatud joonisel fig. 5.
Tabeliandmete saamiseks ettevõtte kasumi kohta iga trendijoone kohta aastatel 1995-2004. Kasutame joonisel fig. 5. Selleks sisestage vahemiku D3:F3 lahtritesse tekstiline teave valitud trendijoone tüübi kohta: Lineaarne trend, Ruuttrend, Kuubitrend. Järgmisena sisestage lahtrisse D4 lineaarse regressiooni valem ja kopeerige see valem täitemarkeri abil koos suhteliste viidetega lahtrite vahemikule D5:D13. Tuleb märkida, et igas lahtris, millel on lineaarse regressioonivalem lahtrite vahemikust D4:D13, on argumendina vastav lahter vahemikust A4:A13. Samamoodi täidetakse ruutregressiooni korral lahtrivahemik E4:E13 ja kuupregressiooni puhul lahtrivahemik F4:F13. Seega koostati ettevõtte kasumiprognoos 2003. ja 2004. aastaks. kolme trendiga. Saadud väärtuste tabel on näidatud joonisel fig. 6.


2. ülesanne
Koostage diagramm.
Lisage diagrammile logaritmilised, eksponentsiaalsed ja eksponentsiaalsed trendijooned.
Tuletage saadud trendijoonte võrrandid, samuti nende kõigi jaoks lähenduskindluse R2 väärtused.
Trendijoone võrrandite abil hankige tabeliandmed ettevõtte kasumi kohta iga trendijoone kohta aastatel 1995–2002.
Tehke nende trendijoonte abil ettevõtte kasumiprognoos aastateks 2003 ja 2004.
Probleemi lahendus
Järgides ülesande 1 lahendamisel antud metoodikat, saame diagrammi, millele on lisatud logaritmilised, eksponentsiaalsed ja eksponentsiaalsed trendijooned (joonis 7). Lisaks täidame saadud trendijoone võrrandite abil ettevõtte kasumi väärtuste tabeli, sealhulgas prognoositud väärtused aastateks 2003 ja 2004. (joonis 8).


Joonisel fig. 5 ja fig. on näha, et logaritmilise trendiga mudel vastab lähenduse usaldusväärsuse madalaimale väärtusele
R2 = 0,8659
R2 suurimad väärtused vastavad polünoomilise trendiga mudelitele: ruut (R2 = 0,9263) ja kuup (R2 = 0,933).
3. ülesanne
Ülesandes 1 toodud autotranspordiettevõtte kasumi andmete tabeliga aastatel 1995-2002 peate tegema järgmised sammud.
Hankige andmeseeriad lineaarsete ja eksponentsiaalsete trendijoonte jaoks, kasutades funktsioone TREND ja GROW.
Tehke TREND ja GROWTH funktsioonide abil ettevõtte kasumiprognoos aastateks 2003 ja 2004.
Algandmete ja vastuvõetud andmeseeriate jaoks koostage diagramm.
Probleemi lahendus
Kasutame ülesande 1 töölehte (vt joonis 4). Alustame funktsiooniga TREND:
valige lahtrite vahemik D4:D11, mis tuleks täita funktsiooni TREND väärtustega, mis vastavad ettevõtte kasumi teadaolevatele andmetele;
kutsuge menüüst Lisa käsk Funktsioon. Valige kuvatavas dialoogiboksis Funktsiooniviisard jaotisest Statistika funktsioon TREND ja seejärel klõpsake nuppu OK. Sama toimingu saab teha vajutades standardse tööriistariba nuppu (funktsioon Insert).
Ilmuvas dialoogiboksis Funktsiooni argumendid sisestage väljale Known_values_y lahtrite vahemik C4:C11; väljal Known_values_x - lahtrite vahemik B4:B11;
sisestatud valemi massiivivalemiks muutmiseks kasutage klahvikombinatsiooni + + .
Valemiribale sisestatud valem näeb välja selline: =(TREND(C4:C11;B4:B11)).
Selle tulemusena täidetakse lahtrite vahemik D4:D11 funktsiooni TREND vastavate väärtustega (joonis 9).

Teha ettevõtte 2003. ja 2004. aasta kasumiprognoos. vajalik:
valige lahtrite vahemik D12:D13, kuhu sisestatakse funktsiooni TREND ennustatud väärtused.
kutsuge välja funktsioon TREND ja ilmuvas dialoogiboksis Funktsiooni argumendid sisestage väljale Known_values_y - lahtrite vahemik C4:C11; väljal Known_values_x - lahtrite vahemik B4:B11; ja väljal Uued_väärtused_x - lahtrite vahemik B12:B13.
muutke see valem massiivivalemiks, kasutades kiirklahvi Ctrl + Shift + Enter.
Sisestatud valem näeb välja selline: =(TREND(C4:C11;B4:B11;B12:B13)) ja lahtrite vahemik D12:D13 täidetakse funktsiooni TREND prognoositud väärtustega (vt joonis 1). 9).
Samamoodi täidetakse andmeseeria funktsiooni GROWTH abil, mida kasutatakse mittelineaarsete sõltuvuste analüüsimisel ja mis toimib täpselt samamoodi nagu selle lineaarne vaste TREND.
Joonis 10 näitab tabelit valemi kuvamise režiimis.


Algandmete ja saadud andmeseeriate jaoks on joonisel fig. üksteist.
4. ülesanne
Mootorveoettevõtte dispetšerteenistuse teenusetaotluste laekumise andmete tabeliga perioodiks jooksva kuu 1. kuni 11. kuupäevani tuleb teha järgmised toimingud.
Hankige andmeseeriad lineaarse regressiooni jaoks: funktsioonide SLOPE ja INTERCEPT abil; kasutades funktsiooni LINEST.
Hankige andmeseeria eksponentsiaalse regressiooni jaoks funktsiooni LYFFPRIB abil.
Kasutades ülaltoodud funktsioone, koosta prognoos taotluste laekumise kohta dispetšerteenistusse jooksva kuu 12.-14. kuupäevaks.
Algse ja vastuvõetud andmeseeria jaoks koostage diagramm.
Probleemi lahendus
Pange tähele, et erinevalt funktsioonidest TREND ja GROW ei ole ükski ülaltoodud funktsioonidest (SLOPE, INTERCEPTION, LINEST, LGRFPRIB) regressioon. Need funktsioonid mängivad ainult abistavat rolli, määrates kindlaks vajalikud regressiooniparameetrid.
Funktsioonide SLOPE, INTERCEPT, LINEST, LGRFINB abil koostatud lineaarsete ja eksponentsiaalsete regressioonide puhul on nende võrrandite välimus alati teada, erinevalt funktsioonidele TREND ja GROWTH vastavatest lineaarsetest ja eksponentsiaalsetest regressioonidest.
1 . Koostame lineaarse regressiooni, millel on võrrand:
y=mx+b
kasutades funktsioone SLOPE ja INTERCEPT, kusjuures regressiooni kalde m määrab funktsioon SLOPE ja konstantne liige b - funktsiooni INTERCEPT abil.
Selleks teostame järgmised toimingud:
sisestage lähtetabel lahtrite vahemikku A4:B14;
parameetri m väärtus määratakse lahtris C19. Valige statistikakategooriast funktsioon Slope; sisestage lahtrite vahemik B4:B14 väljale teadaolevad_väärtused_y ja lahtrite vahemik A4:A14 väljale teadaolevad_väärtused_x. Valem sisestatakse lahtrisse C19: =SLOPE(B4:B14;A4:A14);
sarnase meetodi abil määratakse parameetri b väärtus lahtris D19. Ja selle sisu näeb välja selline: = INTERCEPT(B4:B14;A4:A14). Seega salvestatakse lineaarse regressiooni koostamiseks vajalike parameetrite m ja b väärtused vastavalt lahtritesse C19, D19;
siis sisestame lahtrisse C4 lineaarse regressiooni valemi kujul: = $ C * A4 + $ D. Selles valemis kirjutatakse lahtrid C19 ja D19 absoluutsete viidetega (lahtri aadress ei tohiks võimaliku kopeerimisega muutuda). Absoluutse viitemärgi $ saab sisestada kas klaviatuurilt või kasutades klahvi F4, pärast kursori asetamist lahtri aadressile. Täitepideme abil kopeerige see valem lahtrite vahemikku C4:C17. Saame soovitud andmeread (joonis 12). Kuna päringute arv on täisarv, peaksite lahtri vormingu akna vahekaardil Number määrama numbrivorminguks komakohtade arvuga 0.
2 . Nüüd koostame võrrandiga antud lineaarse regressiooni:
y=mx+b
kasutades funktsiooni LINEST.
Selle jaoks:
sisestage funktsioon LINEST massiivivalemina lahtrite vahemikku C20:D20: =(LINEST(B4:B14;A4:A14)). Selle tulemusena saame parameetri m väärtuse lahtris C20 ja parameetri b väärtuse lahtris D20;
sisesta lahtrisse D4 valem: =$C*A4+$D;
kopeerige see valem täitemarkeri abil lahtrite vahemikku D4:D17 ja hankige soovitud andmeseeria.
3 . Koostame eksponentsiaalse regressiooni, millel on võrrand:
LGRFPRIBL funktsiooni abil teostatakse seda sarnaselt:
lahtrite vahemikku C21:D21 sisestage massiivivalemina funktsioon LGRFPRIBL: =( LGRFPRIBL (B4:B14;A4:A14)). Sel juhul määratakse parameetri m väärtus lahtris C21 ja parameetri b väärtus lahtris D21;
valem sisestatakse lahtrisse E4: =$D*$C^A4;
täitemarkerit kasutades kopeeritakse see valem lahtrite vahemikku E4:E17, kus paiknevad eksponentsiaalse regressiooni andmeread (vt joonis 12).

Joonisel fig. 13 näitab tabelit, kus näeme funktsioone, mida kasutame koos vajalike lahtrivahemikega, ja ka valemeid.
Väärtus R 2 helistas määramiskoefitsient.
Regressioonisõltuvuse konstrueerimise ülesandeks on leida mudeli (1) koefitsientide m vektor, mille juures koefitsient R saab suurima väärtuse.
R-i olulisuse hindamiseks kasutatakse Fisheri F-testi, mis arvutatakse valemiga

Kus n- valimi suurus (katsete arv);
k on mudeli koefitsientide arv.
Kui F ületab mõne andmete kriitilise väärtuse n Ja k ja aktsepteeritud usaldusnivoo, siis loetakse R väärtus oluliseks. F kriitiliste väärtuste tabelid on toodud matemaatilise statistika teatmeteostes.
Seega määrab R olulisuse mitte ainult selle väärtus, vaid ka katsete arvu ja mudeli koefitsientide (parameetrite) arvu suhe. Tõepoolest, lihtsa lineaarse mudeli korrelatsioonisuhe n=2 on 1 (tasapinna kahe punkti kaudu saate alati tõmmata ühe sirge). Kui aga katseandmed on juhuslikud muutujad, tuleks sellist R väärtust väga hoolikalt usaldada. Tavaliselt on olulise R ja usaldusväärse regressiooni saamiseks suunatud sellele, et katsete arv ületaks oluliselt mudeli koefitsientide arvu (n>k).
Lineaarse regressioonimudeli koostamiseks peate:
1) koostage katseandmeid sisaldav n rea ja m veeru loend (väljundväärtust sisaldav veerg Y peab olema loendis esimene või viimane); Näiteks võtame eelmise ülesande andmed, lisades veeru nimega "perioodi number", nummerdades perioodide arvud vahemikus 1 kuni 12. (need on väärtused X)
2) minge menüüsse Data/Data Analysis/Regression

Kui menüüst "Tööriistad" on puudu "Andmete analüüs", siis tuleks minna sama menüü punkti "Lisandmoodulid" ja teha linnuke ruut "Analüüsipakett".
3) määrake dialoogiboksis "Regression":
sisestusintervall Y;
sisestusintervall X;
väljundi intervall - intervalli ülemine vasakpoolne lahter, kuhu arvutustulemused paigutatakse (soovitav on asetada see uuele töölehel);

4) klõpsake "Ok" ja analüüsige tulemusi.
Kui mõni füüsikaline suurus sõltub teisest suurusest, saab seda sõltuvust uurida, mõõtes y-d x erinevatel väärtustel. Mõõtmiste tulemusena saadakse rida väärtusi:
x 1 , x 2 , ..., x i , ... , x n ;
y 1 , y 2 , ..., y i , ... , y n .
Sellise katse andmete põhjal on võimalik joonistada sõltuvus y = ƒ(x). Saadud kõver võimaldab hinnata funktsiooni ƒ(x) kuju. Sellesse funktsiooni sisenevad konstantsed koefitsiendid jäävad aga teadmata. Neid saab määrata vähimruutude meetodil. Katsepunktid ei asu reeglina täpselt kõveral. Vähimruutude meetod eeldab, et katsepunktide kõverast kõrvalekallete ruudu summa, s.o. 2 oli väikseim.
Praktikas kasutatakse seda meetodit kõige sagedamini (ja kõige lihtsamalt) lineaarse seose korral, s.o. Millal
y=kx või y = a + bx.
Lineaarne sõltuvus on füüsikas väga levinud. Ja isegi kui sõltuvus on mittelineaarne, püütakse tavaliselt graafikut koostada nii, et saadakse sirgjoon. Näiteks kui eeldada, et klaasi n murdumisnäitaja on seotud valguslaine lainepikkusega λ suhtega n = a + b/λ 2, siis n sõltuvus λ -2-st kantakse graafikule. .
Mõelge sõltuvusele y=kx(orige, mis läbib alguspunkti). Koostame väärtuse φ meie punktide sirgest kõrvalekallete ruudu summa
φ väärtus on alati positiivne ja osutub väiksemaks, seda lähemal on meie punktid sirgele. Vähimruutude meetod ütleb, et k jaoks tuleks valida selline väärtus, mille juures φ on miinimum
![]()
või
(19)
Arvutus näitab, et k väärtuse määramise ruutkeskmise viga on võrdne
 , (20)
, (20)
kus n on mõõtmete arv.
Vaatleme nüüd mõnevõrra raskemat juhtumit, kui punktid peavad valemile vastama y = a + bx(sirge, mis ei läbi alguspunkti).
Ülesandeks on antud väärtuste hulgast x i , y i leida a ja b parimad väärtused.
Jällegi koostame ruutkuju φ, mis võrdub punktide x i , y i sirgest kõrvalekallete ruudu summaga
![]()
ja leida väärtused a ja b, mille jaoks φ on miinimum
![]() ;
;
![]() .
.
Nende võrrandite ühislahendus annab
![]() (21)
(21)
A ja b määramise ruutkeskmised vead on võrdsed
 (23)
(23)
 . (24)
. (24)
Mõõtmistulemuste töötlemisel sellel meetodil on mugav koondada kõik andmed tabelisse, milles on eelnevalt välja arvutatud kõik valemites (19)(24) sisalduvad summad. Nende tabelite vormid on näidatud allolevates näidetes.
Näide 1 Uuriti pöörleva liikumise dünaamika põhivõrrandit ε = M/J (algopunkti läbiv sirgjoon). Momendi M erinevate väärtuste korral mõõdeti teatud keha nurkiirendust ε. On vaja kindlaks määrata selle keha inertsimoment. Jõumomendi ja nurkkiirenduse mõõtmise tulemused on loetletud teises ja kolmandas veerus tabelid 5.
Tabel 5
| n | M, N m | e, s-1 | M2 | M ε | ε - kM | (ε - kM) 2 |
| 1 | 1.44 | 0.52 | 2.0736 | 0.7488 | 0.039432 | 0.001555 |
| 2 | 3.12 | 1.06 | 9.7344 | 3.3072 | 0.018768 | 0.000352 |
| 3 | 4.59 | 1.45 | 21.0681 | 6.6555 | -0.08181 | 0.006693 |
| 4 | 5.90 | 1.92 | 34.81 | 11.328 | -0.049 | 0.002401 |
| 5 | 7.45 | 2.56 | 55.5025 | 19.072 | 0.073725 | 0.005435 |
| ∑ | | | 123.1886 | 41.1115 | | 0.016436 |
Valemiga (19) määrame:
![]() .
.
Ruutkeskmise vea määramiseks kasutame valemit (20)
0.005775kg-1 · m -2 .
Valemi (18) järgi on meil

SJ = (2,996 0,005775) / 0,3337 = 0,05185 kg m 2.
Arvestades usaldusväärsust P = 0,95, leiame Studenti koefitsientide tabeli järgi n = 5 korral t = 2,78 ja määrame absoluutse vea ΔJ = 2,78 0,05185 = 0,1441 ≈ 0,2 kg m 2.
Kirjutame tulemused kujul:
J = (3,0 ± 0,2) kg m 2;
Näide 2 Arvutame metalli temperatuuri takistuse koefitsiendi vähimruutude meetodil. Vastupidavus sõltub temperatuurist vastavalt lineaarsele seadusele
R t \u003d R 0 (1 + α t °) \u003d R 0 + R 0 α t °.
Vaba liige määrab takistuse R 0 temperatuuril 0 ° C ja nurkkoefitsient on temperatuuriteguri α ja takistuse R 0 korrutis.
Mõõtmiste ja arvutuste tulemused on toodud tabelis ( vaata tabelit 6).
Tabel 6
| n | t°, s | r, ohm | t-¯t | (t-¯t) 2 | (t-¯t)r | r-bt-a | (r - bt - a) 2,10 -6 |
| 1 | 23 | 1.242 | -62.8333 | 3948.028 | -78.039 | 0.007673 | 58.8722 |
| 2 | 59 | 1.326 | -26.8333 | 720.0278 | -35.581 | -0.00353 | 12.4959 |
| 3 | 84 | 1.386 | -1.83333 | 3.361111 | -2.541 | -0.00965 | 93.1506 |
| 4 | 96 | 1.417 | 10.16667 | 103.3611 | 14.40617 | -0.01039 | 107.898 |
| 5 | 120 | 1.512 | 34.16667 | 1167.361 | 51.66 | 0.021141 | 446.932 |
| 6 | 133 | 1.520 | 47.16667 | 2224.694 | 71.69333 | -0.00524 | 27.4556 |
| ∑ | 515 | 8.403 | | 8166.833 | 21.5985 | | 746.804 |
| ∑/n | 85.83333 | 1.4005 | | | | | |
Valemite (21), (22) abil määrame
R 0 = ¯ R- α R 0 ¯ t = 1,4005 - 0,002645 85,83333 = 1,1735 Ohm.
Leiame α definitsioonis vea. Kuna , siis valemiga (18) on meil:
 .
.
Kasutades valemeid (23), (24) saame

 ;
;
0.014126 Ohm.
Arvestades usaldusväärsust P = 0,95, leiame Studenti koefitsientide tabeli järgi n = 6 korral t = 2,57 ja määrame absoluutvea Δα = 2,57 0,000132 = 0,000338 kraad -1.
α = (23 ± 4) 10 -4 rahe-1 at P = 0,95.
Näide 3 Newtoni rõngaste põhjal on vaja määrata läätse kõverusraadius. Mõõdeti Newtoni rõngaste raadiused r m ja määrati nende rõngaste m arvud. Newtoni rõngaste raadiused on võrrandi abil seotud läätse R kõverusraadiusega ja rõnga numbriga
r 2 m = mλR - 2d 0 R,
kus d 0 läätse ja tasapinnalise paralleelse plaadi vahelise pilu paksus (või läätse deformatsioon),
λ on langeva valguse lainepikkus.
λ = (600 ± 6) nm;
r2 m = y;
m = x;
λR = b;
-2d 0 R = a,
siis võtab võrrand kuju y = a + bx.
.Mõõtmiste ja arvutuste tulemused sisestatakse tabel 7.
Tabel 7
| n | x = m | y \u003d r 2, 10 -2 mm 2 | m-¯m | (m-¯m) 2 | (m-¯m) a | y-bx-a, 10-4 | (y - bx - a) 2, 10 -6 |
| 1 | 1 | 6.101 | -2.5 | 6.25 | -0.152525 | 12.01 | 1.44229 |
| 2 | 2 | 11.834 | -1.5 | 2.25 | -0.17751 | -9.6 | 0.930766 |
| 3 | 3 | 17.808 | -0.5 | 0.25 | -0.08904 | -7.2 | 0.519086 |
| 4 | 4 | 23.814 | 0.5 | 0.25 | 0.11907 | -1.6 | 0.0243955 |
| 5 | 5 | 29.812 | 1.5 | 2.25 | 0.44718 | 3.28 | 0.107646 |
| 6 | 6 | 35.760 | 2.5 | 6.25 | 0.894 | 3.12 | 0.0975819 |
| ∑ | 21 | 125.129 | | 17.5 | 1.041175 | | 3.12176 |
| ∑/n | 3.5 | 20.8548333 | | | | | |
Regressioonifunktsiooni tüübi valimine, s.o. vaadeldava mudeli tüüp Y-st X-st (või X-st Y-st), näiteks lineaarne mudel y x = a + bx, on vaja kindlaks määrata mudeli koefitsientide konkreetsed väärtused.
A ja b erinevate väärtuste jaoks on võimalik konstrueerida lõpmatu arv sõltuvusi kujul y x =a+bx, st koordinaattasandil on lõpmatu arv sirgeid, kuid meil on vaja sellist sõltuvust, vastab vaadeldud väärtustele parimal viisil. Seega taandub probleem parimate koefitsientide valikule.
Otsime lineaarset funktsiooni a + bx, mis põhineb ainult teatud arvul saadaolevatel vaatlustel. Vaadeldud väärtustega kõige paremini sobiva funktsiooni leidmiseks kasutame vähimruutude meetodit.
Tähistage: Y i - võrrandiga Y i =a+bx i arvutatud väärtus. y i - mõõdetud väärtus, ε i =y i -Y i - mõõdetud ja arvutatud väärtuste erinevus, ε i =y i -a-bx i.
Vähimruutude meetod eeldab, et ε i, mõõdetud y i ja võrrandist arvutatud Y i väärtuste erinevus, oleks minimaalne. Seetõttu leiame koefitsiendid a ja b nii, et vaadeldud väärtuste ruutude kõrvalekallete summa sirge regressioonijoone väärtustest on väikseim:
Uurides seda argumentide a funktsiooni ja kasutades ekstreemumi tuletisi, saame tõestada, et funktsioon saab minimaalse väärtuse, kui koefitsiendid a ja b on süsteemi lahendid:
 (2)
(2)
Kui jagame normaalvõrrandi mõlemad pooled n-ga, saame:

Arvestades seda  (3)
(3)
Hangi  , siit, asendades esimeses võrrandis a väärtuse, saame:
, siit, asendades esimeses võrrandis a väärtuse, saame:

Sel juhul b nimetatakse regressioonikordajaks; a nimetatakse regressioonivõrrandi vabaks liikmeks ja see arvutatakse järgmise valemiga:
Saadud sirge on teoreetilise regressioonijoone hinnang. Meil on:
Niisiis, ![]() on lineaarse regressiooni võrrand.
on lineaarse regressiooni võrrand.
Regressioon võib olla otsene (b>0) ja pöördvõrdeline (b Näide 1. X- ja Y-väärtuste mõõtmise tulemused on toodud tabelis:
| x i | -2 | 0 | 1 | 2 | 4 |
| y i | 0.5 | 1 | 1.5 | 2 | 3 |
Eeldades, et X ja Y vahel on lineaarne seos y=a+bx, määrake koefitsiendid a ja b vähimruutude meetodil.
Lahendus. Siin n=5
x i =-2+0+1+2+4=5;
x i 2 =4+0+1+4+16=25
x i y i =-2 0,5+0 1+1 1,5+2 2+4 3=16,5
y i =0,5+1+1,5+2+3=8
ja tavasüsteemil (2) on vorm ![]()
Selle süsteemi lahendades saame: b=0,425, a=1,175. Seega y=1,175+0,425x.
Näide 2. Valim koosneb 10 majandusnäitajate (X) ja (Y) vaatlusest.
| x i | 180 | 172 | 173 | 169 | 175 | 170 | 179 | 170 | 167 | 174 |
| y i | 186 | 180 | 176 | 171 | 182 | 166 | 182 | 172 | 169 | 177 |
On vaja leida näidisregressioonivõrrand Y punktis X. Koostada näidisregressioonisirge Y punktis X.
Lahendus. 1. Sorteerime andmed väärtuste x i ja y i järgi. Saame uue tabeli:
| x i | 167 | 169 | 170 | 170 | 172 | 173 | 174 | 175 | 179 | 180 |
| y i | 169 | 171 | 166 | 172 | 180 | 176 | 177 | 182 | 182 | 186 |
Arvutuste lihtsustamiseks koostame arvutustabeli, kuhu sisestame vajalikud arvväärtused.
| x i | y i | x i 2 | x i y i |
| 167 | 169 | 27889 | 28223 |
| 169 | 171 | 28561 | 28899 |
| 170 | 166 | 28900 | 28220 |
| 170 | 172 | 28900 | 29240 |
| 172 | 180 | 29584 | 30960 |
| 173 | 176 | 29929 | 30448 |
| 174 | 177 | 30276 | 30798 |
| 175 | 182 | 30625 | 31850 |
| 179 | 182 | 32041 | 32578 |
| 180 | 186 | 32400 | 33480 |
| ∑x i =1729 | ∑y i =1761 | ∑x i 2 299105 | ∑x i y i =304696 |
| x = 172,9 | y = 176,1 | x i 2 = 29910,5 | xy = 30469.6 |
Valemi (4) järgi arvutame regressioonikordaja
ja valemiga (5)
Seega näeb valimi regressioonivõrrand välja y=-59,34+1,3804x.
Joonistame punktid (x i ; y i) koordinaattasandile ja märgime regressioonisirge.

Joonis 4
Joonisel 4 on näidatud, kuidas vaadeldud väärtused paiknevad regressioonijoone suhtes. Y i kõrvalekallete arvuliseks hindamiseks Y i-st, kus y i on vaadeldud väärtused ja Y i on regressiooniga määratud väärtused, koostame tabeli:
| x i | y i | Y i | Y i -y i |
| 167 | 169 | 168.055 | -0.945 |
| 169 | 171 | 170.778 | -0.222 |
| 170 | 166 | 172.140 | 6.140 |
| 170 | 172 | 172.140 | 0.140 |
| 172 | 180 | 174.863 | -5.137 |
| 173 | 176 | 176.225 | 0.225 |
| 174 | 177 | 177.587 | 0.587 |
| 175 | 182 | 178.949 | -3.051 |
| 179 | 182 | 184.395 | 2.395 |
| 180 | 186 | 185.757 | -0.243 |
Y i väärtused arvutatakse regressioonivõrrandi järgi.
Mõnede täheldatud väärtuste märgatav kõrvalekalle regressioonijoonest on seletatav vaatluste väikese arvuga. Uurides Y lineaarse sõltuvuse astet X-st, võetakse arvesse vaatluste arvu. Sõltuvuse tugevuse määrab korrelatsioonikordaja väärtus.
Ülesanne on leida lineaarsed sõltuvuskoefitsiendid, mille puhul on kahe muutuja funktsioon A Ja b võtab väikseima väärtuse. St andmeid arvestades A Ja b katseandmete ruutude hälvete summa leitud sirgest on väikseim. See on kogu vähimruutude meetodi mõte.
Seega taandatakse näite lahendus kahe muutuja funktsiooni ekstreemumi leidmisele.
Valemite tuletamine koefitsientide leidmiseks. Koostatakse ja lahendatakse kahest võrrandist koosnev süsteem kahe tundmatuga. Funktsioonide osatuletiste leidmine ![]() muutujate järgi A Ja b, võrdsustame need tuletised nulliga.
muutujate järgi A Ja b, võrdsustame need tuletised nulliga.

Lahendame saadud võrrandisüsteemi mis tahes meetodiga (näiteks asendusmeetod või Crameri meetod) ja saame valemid koefitsientide leidmiseks vähimruutude meetodil (LSM). 
Andmetega A Ja b funktsiooni ![]() võtab väikseima väärtuse.
võtab väikseima väärtuse.
See on kogu vähimruutude meetod. Valem parameetri leidmiseks a sisaldab summasid , , , ja parameetrit n- katseandmete hulk. Nende summade väärtused on soovitatav arvutada eraldi. Koefitsient b leitud pärast arvutamist a.
Selliste polünoomide peamine rakendusvaldkond on eksperimentaalsete andmete töötlemine (empiiriliste valemite koostamine). Fakt on see, et katse abil saadud funktsiooni väärtustest konstrueeritud interpolatsioonipolünoomi mõjutab tugevalt "katsemüra", pealegi ei saa interpoleerimise ajal interpolatsioonisõlmi korrata, s.t. korduvate katsete tulemusi ei saa kasutada samadel tingimustel. Ruutkeskmise polünoom tasandab müra ja võimaldab kasutada mitme katse tulemusi.
Numbriline integreerimine ja diferentseerimine. Näide.
Numbriline integreerimine- kindla integraali väärtuse arvutamine (reeglina ligikaudne). Numbrilise integreerimise all mõistetakse arvuliste meetodite kogumit teatud integraali väärtuse leidmiseks.
Numbriline eristamine– meetodite kogum diskreetselt etteantud funktsiooni tuletise väärtuse arvutamiseks.
Integratsioon
Probleemi sõnastamine.Ülesande matemaatiline lause: on vaja leida teatud integraali väärtus
kus a, b on lõplikud, f(x) on pidev punktil [а, b].
Praktiliste ülesannete lahendamisel juhtub sageli, et integraali on ebamugav või võimatu analüütiliselt võtta: seda ei pruugita elementaarfunktsioonides väljendada, integrandi saab anda tabeli kujul jne. Sellistel juhtudel kasutatakse arvulise integreerimise meetodeid. kasutatud. Numbrilised integreerimismeetodid kasutavad kõverjoonelise trapetsi pindala asendamist lihtsamate geomeetriliste kujundite pindalade lõpliku summaga, mida saab täpselt arvutada. Selles mõttes räägitakse kvadratuurivalemite kasutamisest.
Enamik meetodeid kasutab integraali esitamist lõpliku summana (kvadratuurivalem):
Kvadratuurivalemid põhinevad ideel asendada integreerimisintervalli integrandi graafik lihtsama kujuga funktsioonidega, mida saab hõlpsasti analüütiliselt integreerida ja seega hõlpsasti arvutada. Lihtsaim kvadratuurvalemite koostamise ülesanne on realiseeritud polünoomsete matemaatiliste mudelite puhul.
Eristada saab kolme meetodite rühma:
1. Meetod lõimimislõigu jagamisega võrdseteks intervallideks. Intervallidele jagamine toimub eelnevalt, tavaliselt valitakse intervallid võrdseks (et oleks lihtsam intervallide otstes funktsiooni arvutada). Arvutage pindalad ja summeerige need (ristkülikute meetodid, trapets, Simpson).
2. Meetodid lõimimise segmendi jagamisega spetsiaalsete punktide abil (Gaussi meetod).
3. Integraalide arvutamine juhuslike arvude abil (Monte Carlo meetod).
Ristküliku meetod. Olgu funktsioon (joonis) lõigule numbriliselt integreeritud. Jagame lõigu N võrdseks intervalliks. Iga N kõverjoonelise trapetsi pindala saab asendada ristküliku pindalaga.

Kõigi ristkülikute laius on sama ja võrdne:
![]()
Ristkülikute kõrguse valikuna saate valida vasakpoolsel äärisel oleva funktsiooni väärtuse. Sel juhul on esimese ristküliku kõrgus f(a), teise ristküliku kõrgus f(x 1),…, N-f(N-1).
Kui võtta ristküliku kõrguse valikuks paremal äärel oleva funktsiooni väärtus, siis sel juhul on esimese ristküliku kõrgus f (x 1), teise - f (x 2), . .., N - f (x N).
Nagu näha, annab üks valemitest sellisel juhul integraalile lähenduse koos liiaga ja teine puudujäägiga. On veel üks võimalus - kasutada lähendamiseks funktsiooni väärtust integreerimissegmendi keskel:
Ristkülikute meetodi absoluutvea hinnang (keskmine)
Vasaku ja parempoolse ristküliku meetodite absoluutvea hindamine.
Näide. Arvutage kogu intervall ja jagage intervall neljaks osaks
Lahendus. Selle integraali analüütiline arvutus annab I=arctg(1)–arctg(0)=0,7853981634. Meie puhul:
1) h = 1; xo = 0; x1 = 1;
2) h = 0,25 (1/4); x0 = 0; x1 = 0,25; x2 = 0,5; x3 = 0,75; x4 = 1;
Arvutame vasakpoolsete ristkülikute meetodil:
![]()
Arvutame täisnurksete ristkülikute meetodil:
![]()
Arvutage keskmiste ristkülikute meetodil:
![]()

Trapetsikujuline meetod. Esimese astme polünoomi kasutamine interpoleerimiseks (sirge, mis on tõmmatud läbi kahe punkti) annab trapetsivalemile. Integratsioonisegmendi otsad võetakse interpolatsioonisõlmedena. Seega asendatakse kõverjooneline trapets tavalise trapetsiga, mille pindala on võimalik leida poole aluste summa ja kõrguse korrutisena.

![]() Kõigi sõlmede, välja arvatud segmendi äärmiste punktide integreerimise N lõigu korral kaasatakse funktsiooni väärtus kogusummasse kaks korda (kuna naabertrapetsidel on üks ühine külg)
Kõigi sõlmede, välja arvatud segmendi äärmiste punktide integreerimise N lõigu korral kaasatakse funktsiooni väärtus kogusummasse kaks korda (kuna naabertrapetsidel on üks ühine külg)
![]()
Trapetsi valemi saab saada, võttes poole ristkülikuvalemite summast piki lõigu paremat ja vasakut serva:
Lahuse stabiilsuse kontrollimine. Reeglina on iga intervalli pikkus lühem, s.t. mida suurem on nende intervallide arv, seda väiksem on erinevus integraali ligikaudsete ja täpsete väärtuste vahel. See kehtib enamiku funktsioonide kohta. Trapetsimeetodil on integraali ϭ arvutamise viga ligikaudu võrdeline integreerimisastme ruuduga (ϭ ~ h 2) Seega on teatud funktsiooni integraali arvutamiseks piirides a, b vaja jaga lõik N 0 intervallideks ja leia trapetsi pindalade summa. Seejärel peate suurendama intervallide arvu N 1, arvutama uuesti trapetsi summa ja võrdlema saadud väärtust eelmise tulemusega. Seda tuleks korrata kuni (N i), kuni saavutatakse tulemuse määratud täpsus (konvergentsikriteerium).
Ristküliku- ja trapetsimeetodi puhul suureneb intervallide arv tavaliselt igal iteratsiooniastmel 2 korda (N i +1 =2N i).
Lähenemiskriteerium:
Trapetsi reegli peamine eelis on selle lihtsus. Kui aga integreerimine nõuab suurt täpsust, võib see meetod nõuda liiga palju iteratsioone.
Trapetsikujulise meetodi absoluutne viga hinnatud kui
.
Näide. Arvutage trapetsi valemi abil ligikaudu kindel integraal.
a) Integratsioonisegmendi jagamine 3 osaks.
b) Integratsiooni segmendi jagamine 5 osaks.
Lahendus:
a) Tingimuse järgi tuleb integratsioonisegment jagada 3 osaks, st.
Arvutage partitsiooni iga segmendi pikkus: ![]() .
.
Seega vähendatakse trapetsi üldvalemit meeldiva suuruseni:

Lõpuks:
Tuletan teile meelde, et saadud väärtus on pindala ligikaudne väärtus.
b) Jagame integreerimislõigu 5 võrdseks osaks, st . segmentide arvu suurendamisega suurendame arvutuste täpsust.
Kui , siis on trapetsi valem järgmine:
Leiame jaotamise etapi: ![]() , see tähendab, et iga vahelõigu pikkus on 0,6.
, see tähendab, et iga vahelõigu pikkus on 0,6.
Ülesande lõpetamisel on mugav koostada kõik arvutused arvutustabeliga:
Esimesel real kirjutame "loendur"
Tulemusena: 
Noh, täpsustus on tõesti olemas ja tõsine!
Kui partitsiooni 3 segmendi jaoks, siis 5 segmendi jaoks. Kui võtate veelgi rohkem segmenti, on => veelgi täpsem.
Simpsoni valem. Trapetsivalem annab tulemuse, mis sõltub tugevalt sammu suurusest h, mis mõjutab kindla integraali arvutamise täpsust, eriti juhtudel, kui funktsioon on mittemonotoonne. Arvutuste täpsuse suurenemist võib eeldada, kui funktsiooni f(x) graafiku kõverjoonelisi fragmente asendavate sirgjoonte segmentide asemel kasutame näiteks graafiku kolme naaberpunkti kaudu antud paraboolide fragmente. . Sarnane geomeetriline tõlgendus on Simpsoni kindla integraali arvutamise meetodi aluseks. Kogu integreerimisintervall a,b on jagatud N segmendiks, lõigu pikkus võrdub samuti h=(b-a)/N.

Simpsoni valem on järgmine:
![]() ülejäänud tähtaeg
ülejäänud tähtaeg
Segmentide pikkuse suurenemisega valemi täpsus väheneb, seetõttu kasutatakse täpsuse suurendamiseks Simpsoni liitvalemit. Kogu integreerimisintervall jagatakse paarisarvuks identseteks lõikudeks N, lõigu pikkus on samuti võrdne h=(b-a)/N. Simpsoni liitvalem on järgmine:
Valemis on sulgudes olevad avaldised integrandi väärtuste summad vastavalt paaritute ja paaritute sisemiste segmentide lõpus.
Simpsoni valemi ülejäänud liige on juba võrdeline astme neljanda astmega:
![]()
Näide: Arvutage integraal Simpsoni reegli abil. (Täpne lahendus – 0,2)


Gaussi meetod
 Gaussi kvadratuurivalem. Teise sordi kvadratuurivalemite põhiprintsiip on näha jooniselt 1.12: punktid on vaja paigutada nii X 0 ja X 1 segmendi sees [ a;b] nii, et "kolmnurkade" pindalad kokku on võrdsed "lõigu" pindaladega. Gaussi valemi kasutamisel on algsegment [ a;b] vähendatakse muutujat muutes intervallile [-1;1] X peal
Gaussi kvadratuurivalem. Teise sordi kvadratuurivalemite põhiprintsiip on näha jooniselt 1.12: punktid on vaja paigutada nii X 0 ja X 1 segmendi sees [ a;b] nii, et "kolmnurkade" pindalad kokku on võrdsed "lõigu" pindaladega. Gaussi valemi kasutamisel on algsegment [ a;b] vähendatakse muutujat muutes intervallile [-1;1] X peal
0.5∙(b– a)∙t+ 0.5∙(b + a).
Siis ![]() , Kus
, Kus ![]() .
.
See asendamine on võimalik, kui a Ja b on lõplikud ja funktsioon f(x) on pidev [ a;b]. Gaussi valem n punktid x i, i=0,1,..,n-1 segmendi sees [ a;b]:
 , (1.27)
, (1.27)
Kus t i Ja Ai erinevatele n on toodud teatmeteostes. Näiteks millal n=2 ![]() A 0 =A 1 = 1; juures n=3: t 0 =t 2" 0,775, t 1 =0, A 0 =A 2" 0,555, A 1" 0,889.
A 0 =A 1 = 1; juures n=3: t 0 =t 2" 0,775, t 1 =0, A 0 =A 2" 0,555, A 1" 0,889.
Gaussi kvadratuurivalem
 saadud kaalufunktsiooniga, mis on võrdne ühega p(x)= 1 ja sõlmed x i, mis on Legendre polünoomide juured
saadud kaalufunktsiooniga, mis on võrdne ühega p(x)= 1 ja sõlmed x i, mis on Legendre polünoomide juured
![]()
Koefitsiendid Ai kergesti arvutatav valemitega
![]() i=0,1,2,...n.
i=0,1,2,...n.
Sõlmede ja koefitsientide väärtused n=2,3,4,5 korral on toodud tabelis
| Telli | Sõlmed | Koefitsiendid |
| n=2 | x 1=0 x 0 =-x2=0.7745966692 | A 1=8/9 A 0 = A 2=5/9 |
| n=3 | x 2 =-x 1=0.3399810436 x 3 =-x0=0.8611363116 | A 1 = A 2=0.6521451549 A 0 = A 3=0.6521451549 |
| n = 4 | x 2 = 0 x 3 = -x 1 = 0.5384693101 x 4 =-x 0 =0.9061798459 | A 0 =0.568888899 A 3 =A 1 =0.4786286705 A 0 =A 4 =0.2869268851 |
| n=5 | x 5 = -x 0 =0.9324695142 x 4 = -x 1 =0.6612093865 x 3 = -x 2 =0.2386191861 | A 5 =A 0 =0.1713244924 A 4 =A 1 =0.3607615730 A 3 =A 2 =0.4679139346 |
Näide. Arvutage väärtus Gaussi valemi abil n=2:
Täpne väärtus: ![]() .
.
Integraali arvutamise algoritm Gaussi valemi järgi ei näe ette mikrosegmentide arvu kahekordistamist, vaid ordinaatide arvu suurendamist 1 võrra ja integraali saadud väärtuste võrdlemist. Gaussi valemi eeliseks on kõrge täpsus suhteliselt väikese ordinaatide arvuga. Puudused: ebamugav käsitsi arvutamiseks; tuleb salvestada arvuti mällu t i, Ai erinevatele n.
Gaussi kvadratuurivalemi viga lõigul on samal ajal Ülejäänud liikme valem on kus koefitsient α N väheneb kasvuga kiiresti N. Siin ![]()
Gaussi valemid annavad suure täpsuse juba väikese arvu sõlmede korral (4 kuni 10) Sel juhul on praktilistes arvutustes sõlmede arv mitmesajast kuni mitme tuhandeni. Samuti märgime, et Gaussi kvadratuuride kaalud on alati positiivsed, mis tagab summade arvutamise algoritmi stabiilsuse